Paper

LEMURS: Learning Distributed Multi-Robot Interactions
IEEE ICRA 2023.
[pdf]
|
|
|
Universidad de Zaragoza |
|
University of California, San Diego |
|
|
|
|
|
|
|
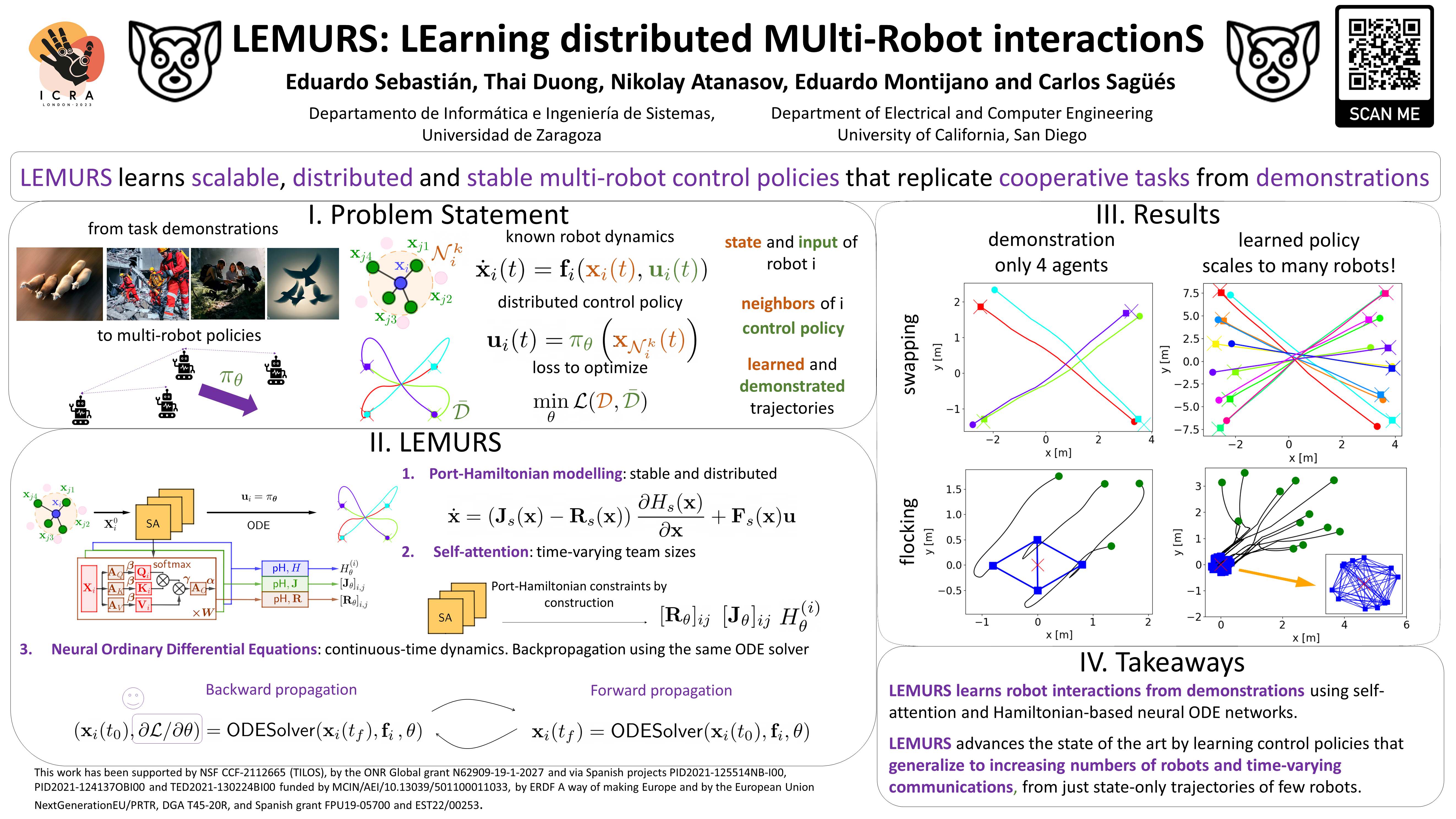
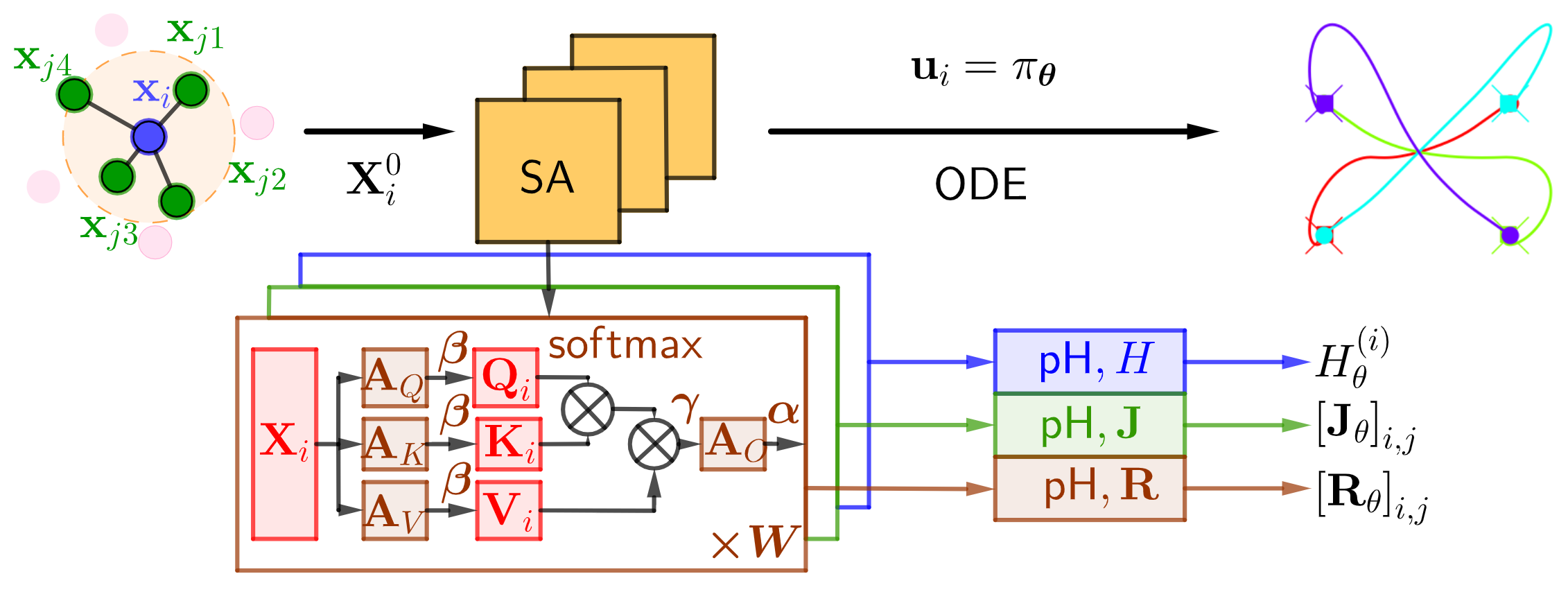
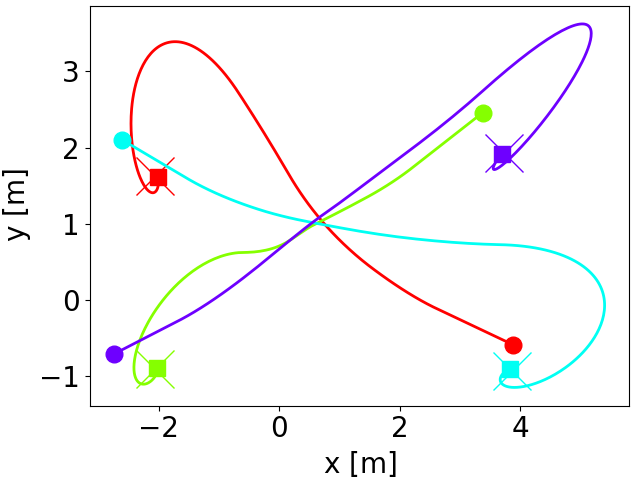
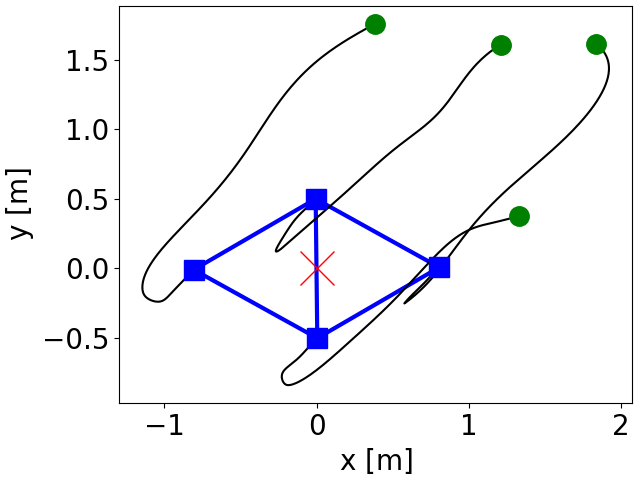
Eduardo Sebastian, Thai Duong, Nikolay Atanasov, Eduardo Montijano and Carlos Sagues LEMURS: Learning Distributed Multi-Robot Interactions IEEE ICRA 2023. [pdf] |
 |
|
|
|
|
 |
|

|
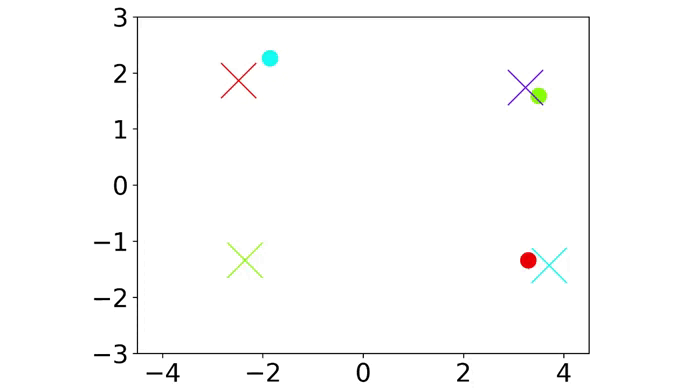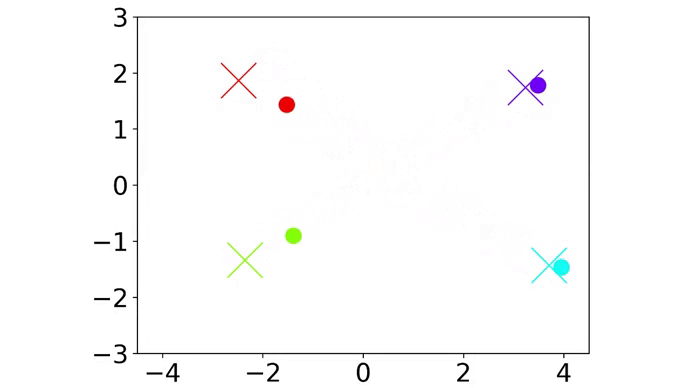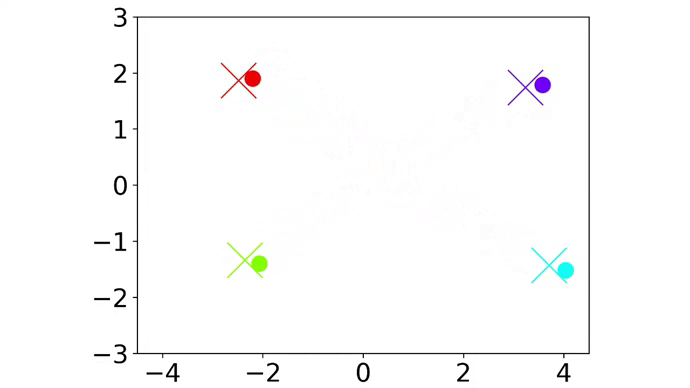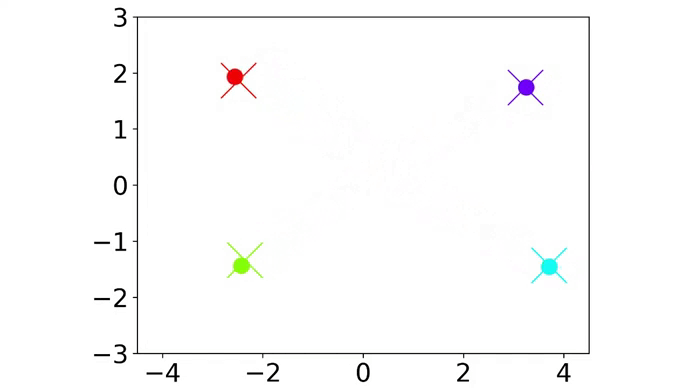
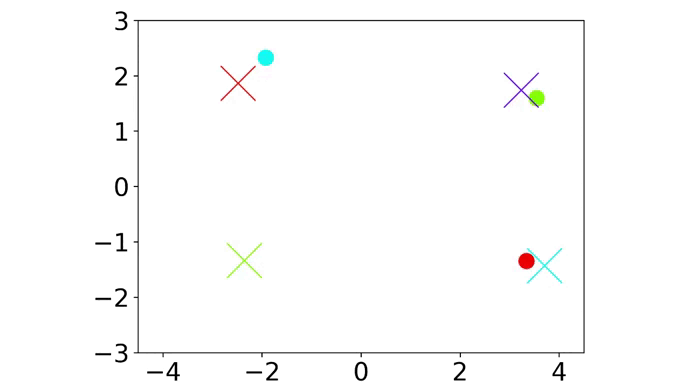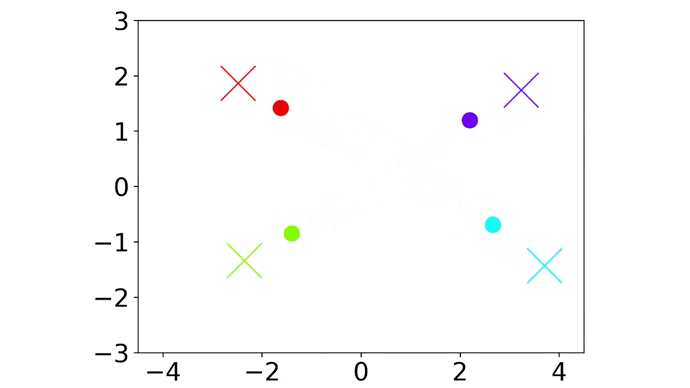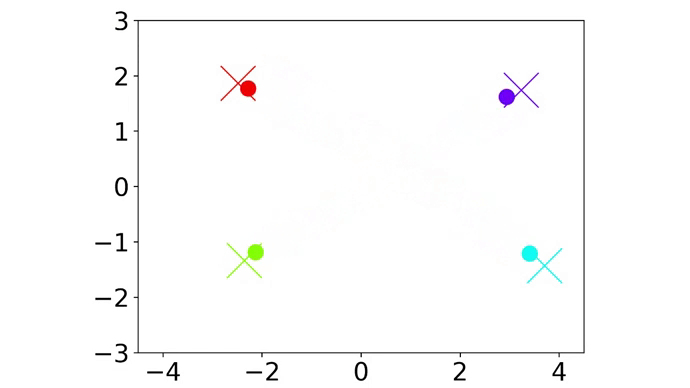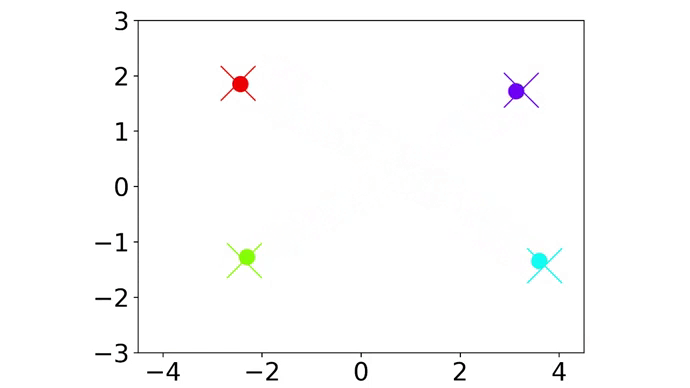
|
|
|

|
|
|

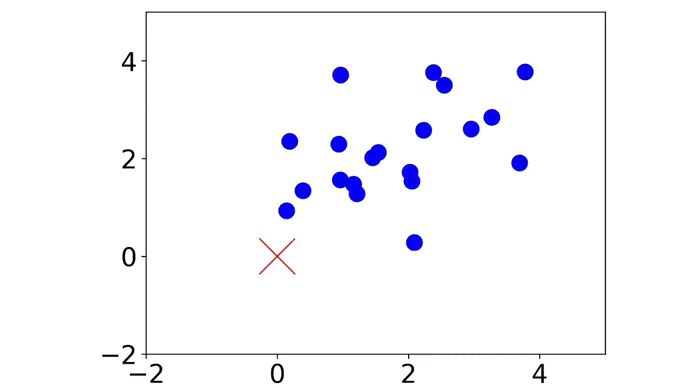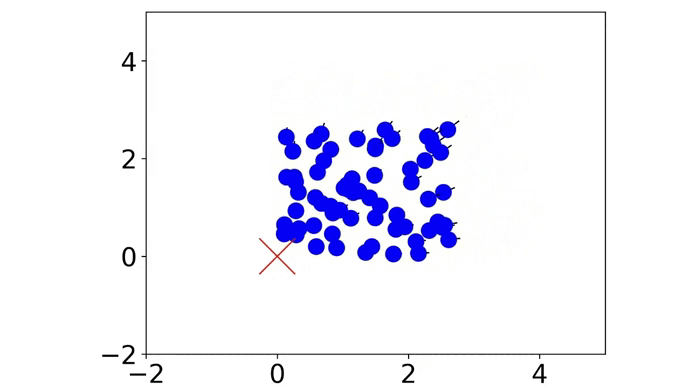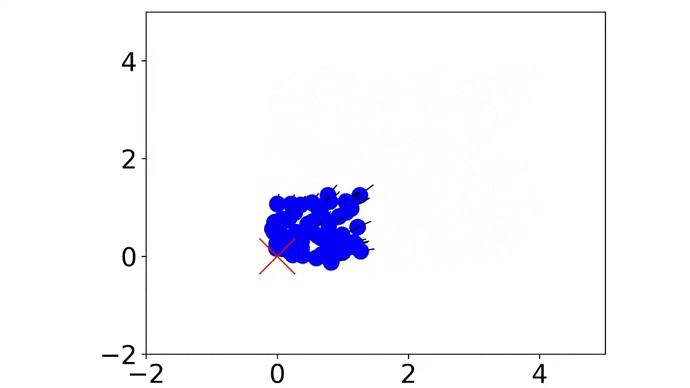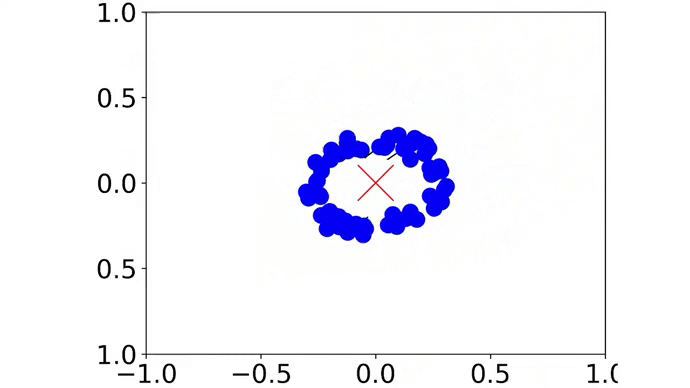
|
|
|
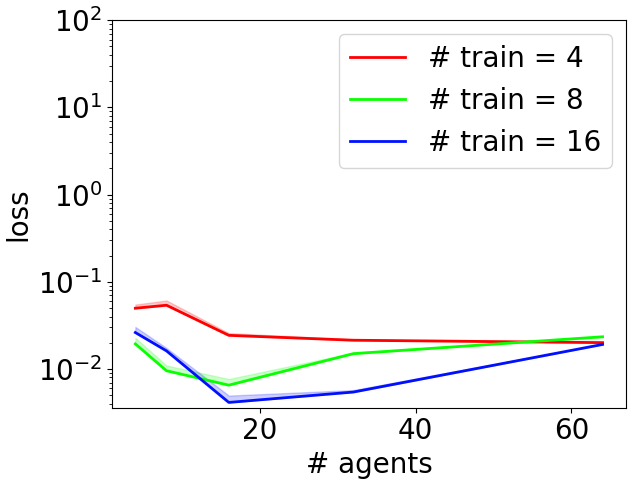
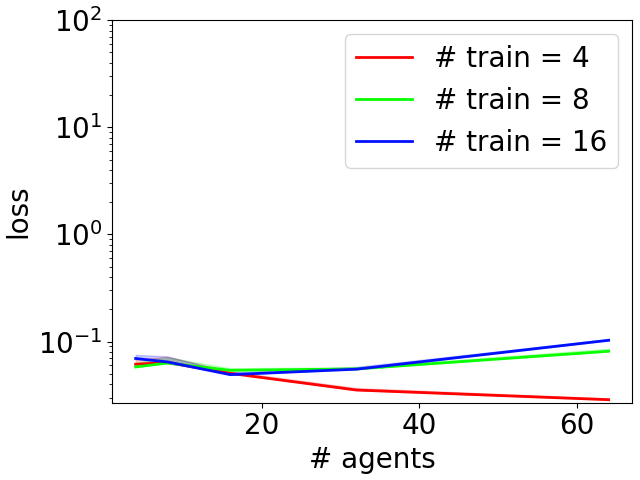
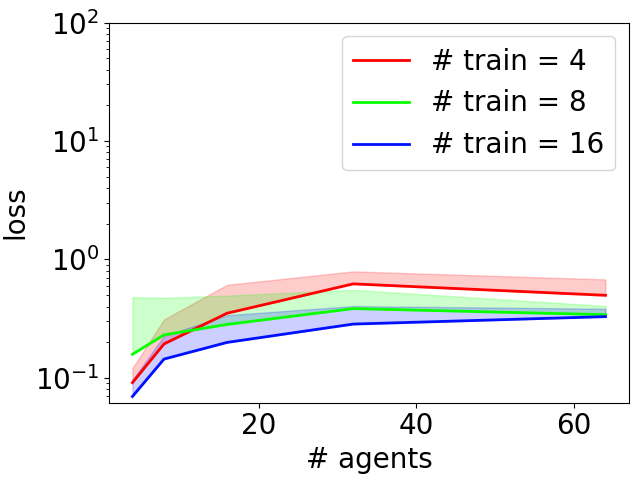
|
|
|

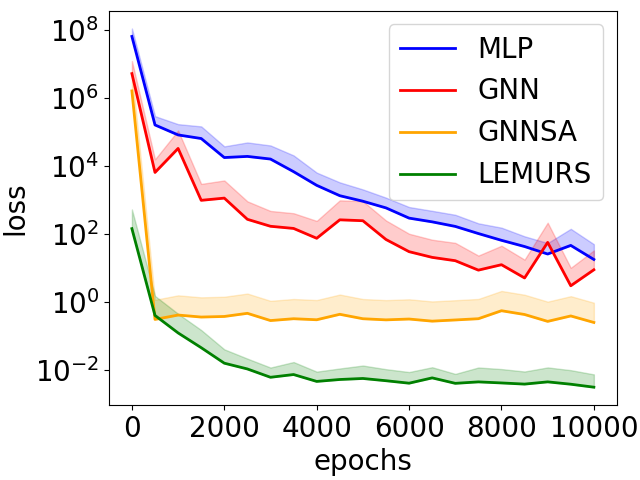

|
|
|
AcknowledgementsThis webpage template was borrowed from https://thaipduong.github.io/SE3HamDL/. |