|
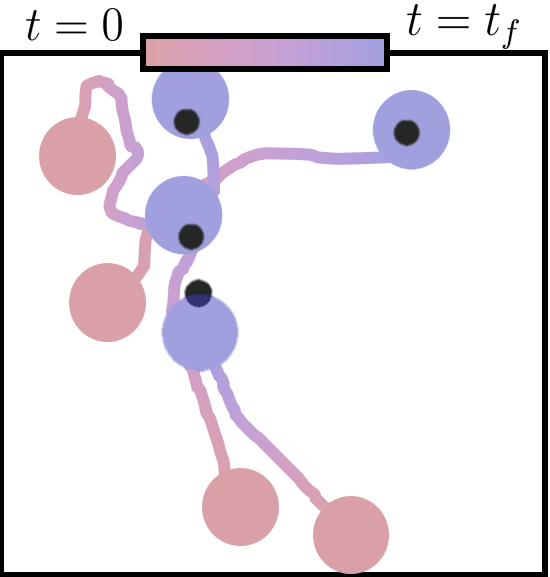
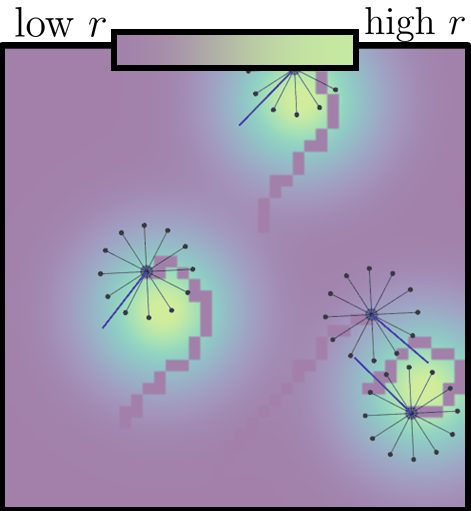
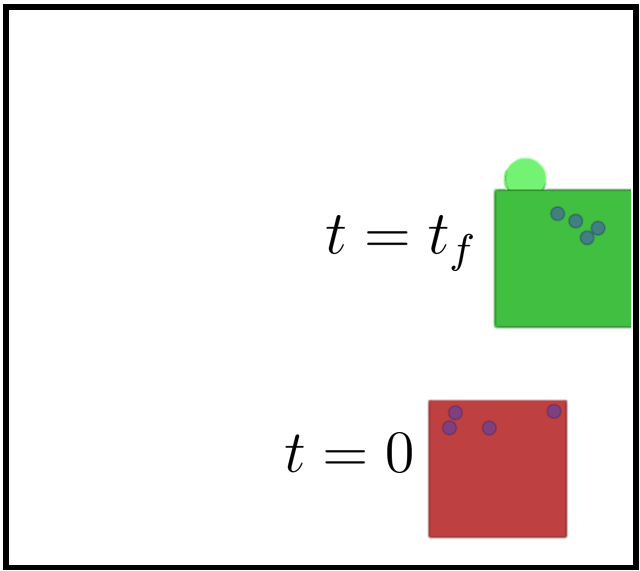
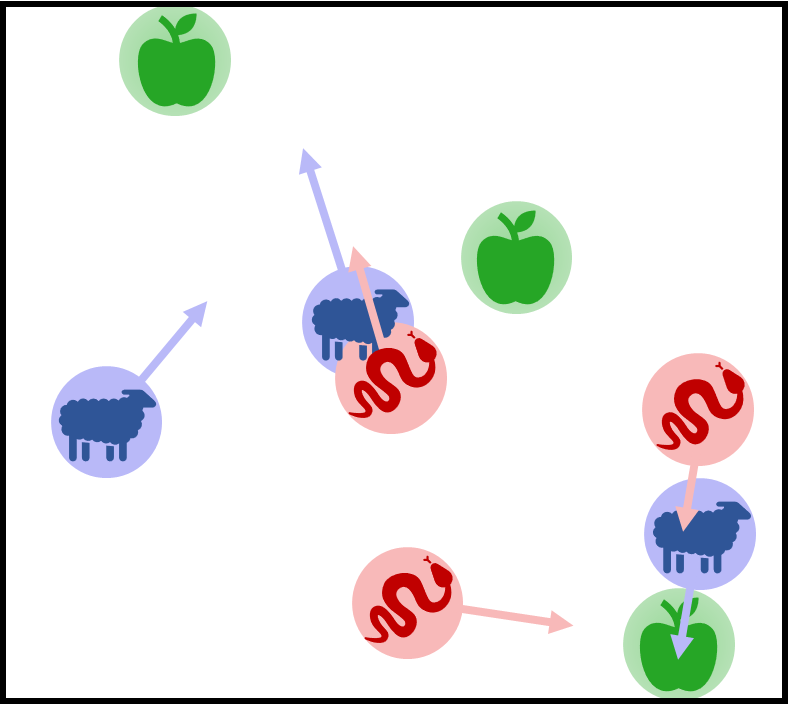
Examples of scenarios addressed by our physics-informed multi-agent reinforcement learning approach. The scenarios cover a wide variety of cooperative/competitive behaviors and levels of coordination complexity. From left to right: (a) robots learn to navigate to landmarks (black dots) while avoiding collisions; (b) robots cooperate to do active LiDAR sampling (orange areas) in an environment with unknown regions of interest (green areas); (c) robots cooperate to transport a squared box (red) towards a desired region (green dot); (d) the robots (blue) collect food (green) while avoiding collisions with attackers (red).
|
|
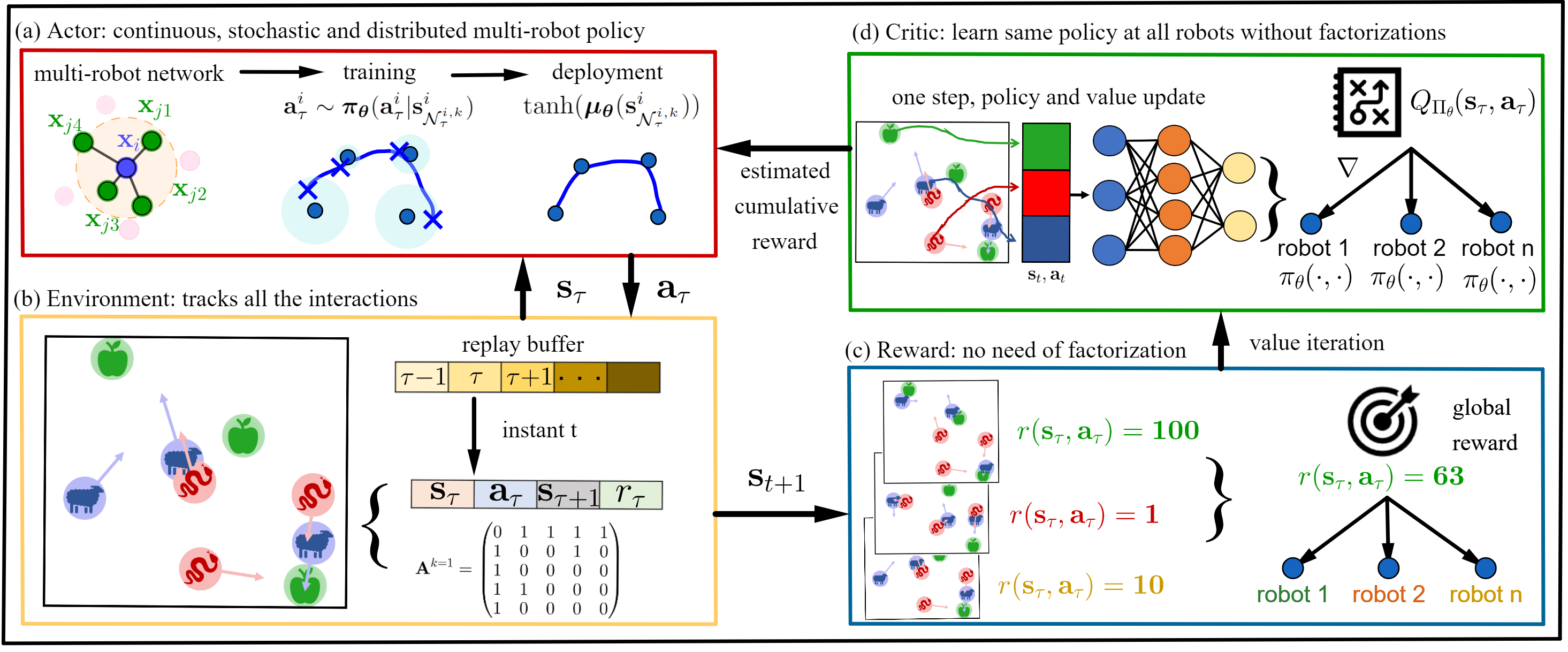
Overview of our physics-informed soft actor-critic multi-agent reinforcement learning approach. The main differences with respect of other actor-critic methods are the following: (a) the actor is the multi-robot network modeled as a port-Hamiltonian system and with a policy given by a self-attention-based IDA-PBC; (b) the replay buffer not only stores action, states and reward, but also the graph structure of the multi-robot network to enforce the desired distributed structure; (c) the reward is global because the actor is the whole multi-robot team and the physics-informed parameterization already conditions the policy on the graph structure of the team; (d) the output of the critic is shared across robots and the policy parameters are the same for all robots, so for the same critic gradient step, n policy gradient steps are taken.
|
|
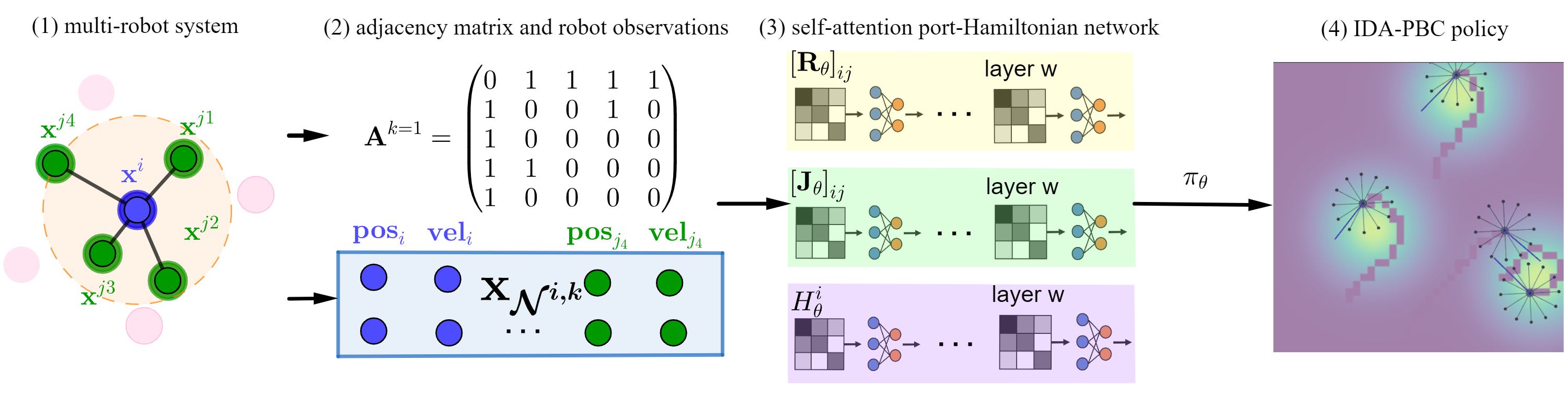
Physics-informed policy parameterization. At each instant, the robot receives state information from its neighbors, typically associated to a perception or communication radius. Then, three self-attention-based modules, each one associated to a component of the desired closed-loop port-Hamiltonian dynamics, uses the information from the neighbors to compute the parameters of the IDA-PBC policy, which is then used to execute the desired control action.
|
|
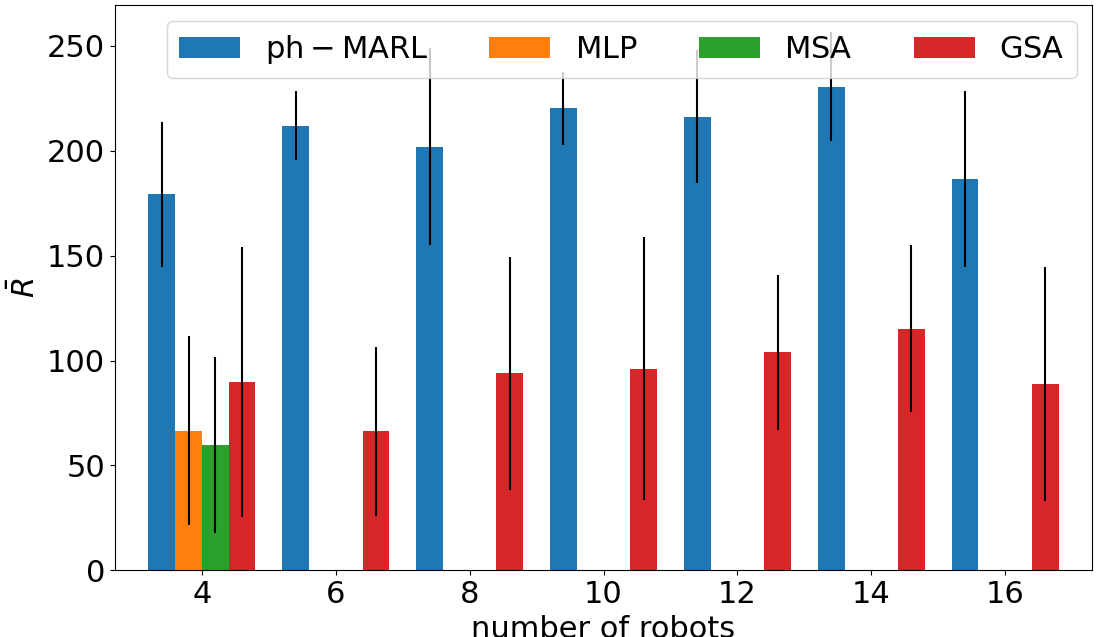
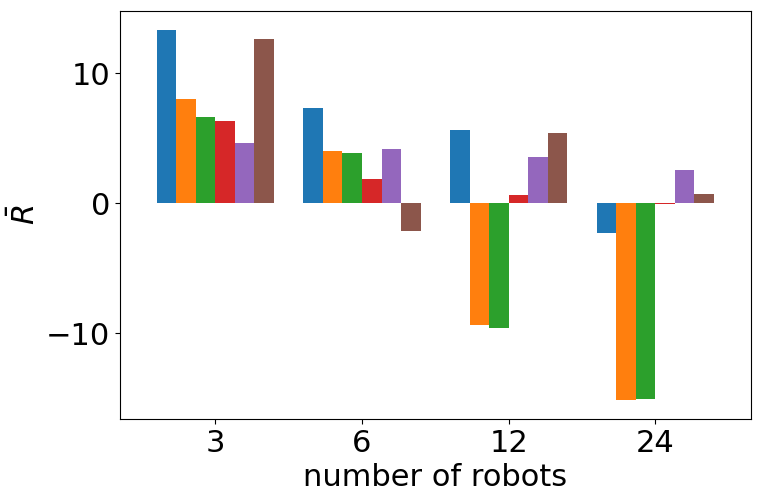
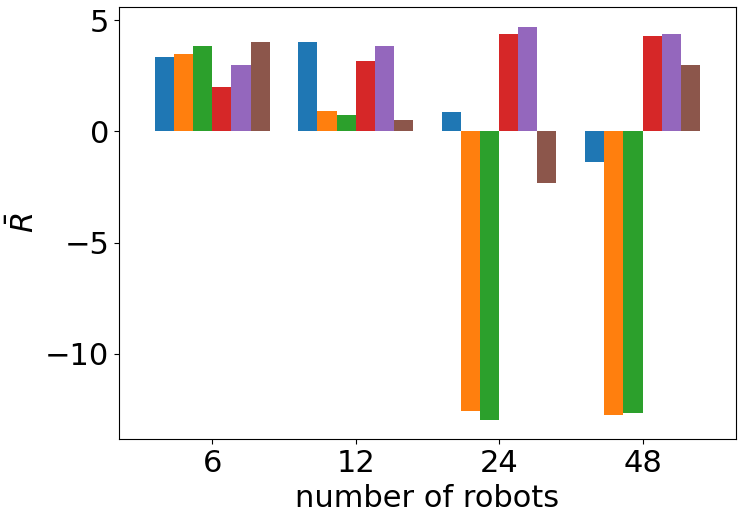
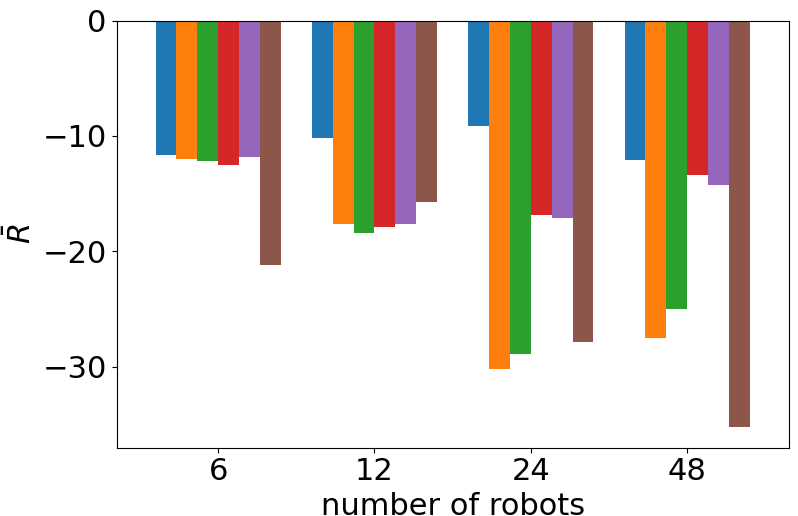
Comparison of the performance of the ablated control policies when we scale the number of robots in deployment. In all the scenarios, our proposed combination of a port-Hamiltonian modeling and self-attention-based neural networks achieves the best cumulative reward without further training the control policy. Each bar displays the mean and standard deviation of the average cumulative reward over 10 evaluation episodes.
|

|
|
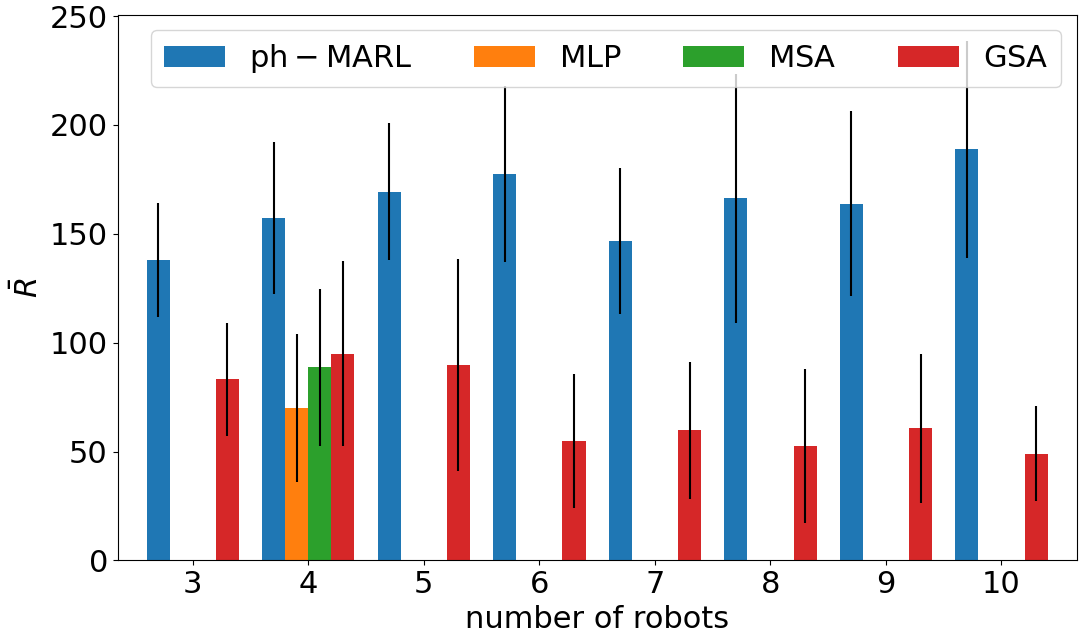
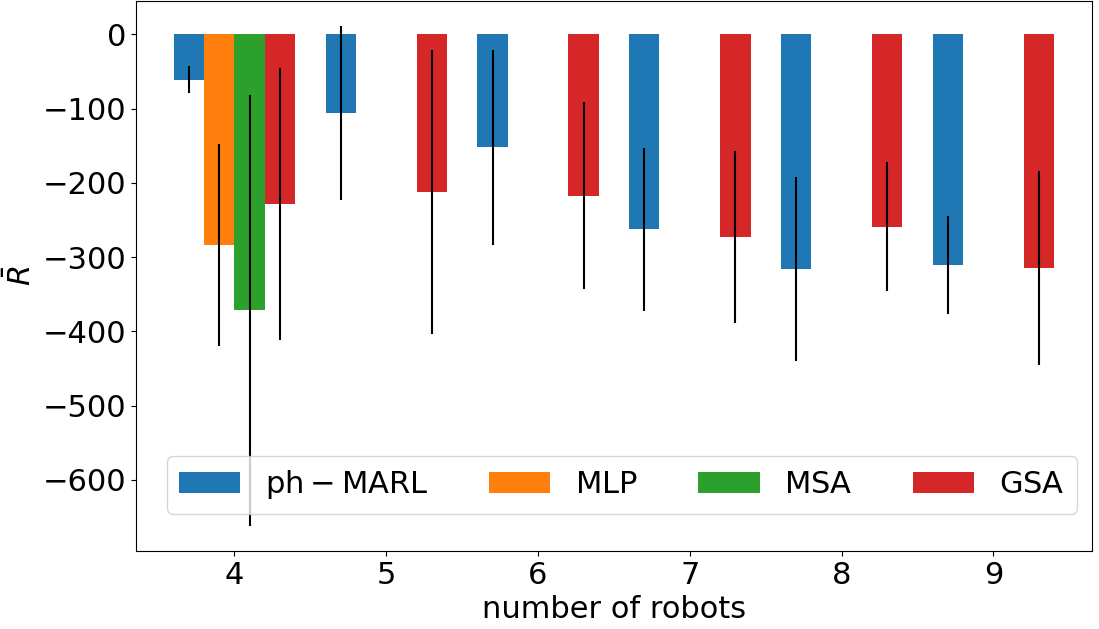
Comparison of our proposed physics-informed multi-agent reinforcement learning approach with other state-of-the-art approaches. pH-MARL is only trained with 4 robots and deployed with different team sizes, while the state-of-the-art control policies are trained for each specific number of robots.
|
Some Qualitative Results
|
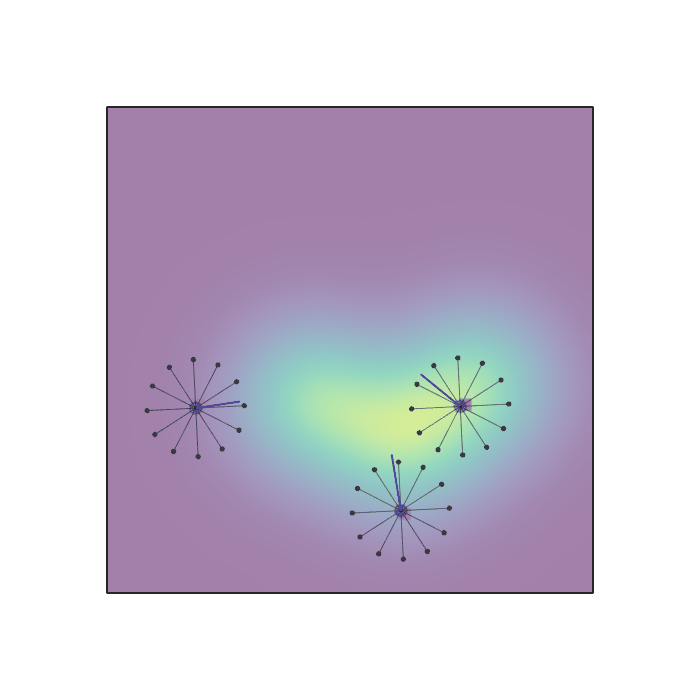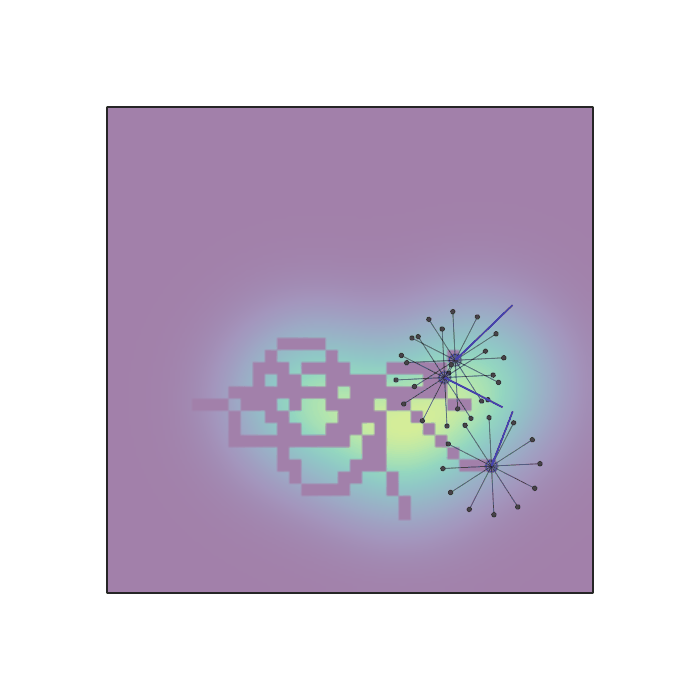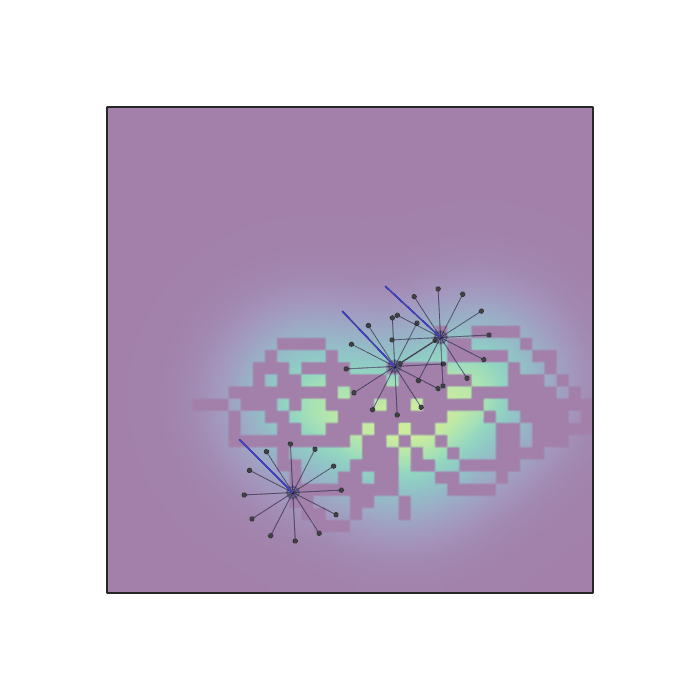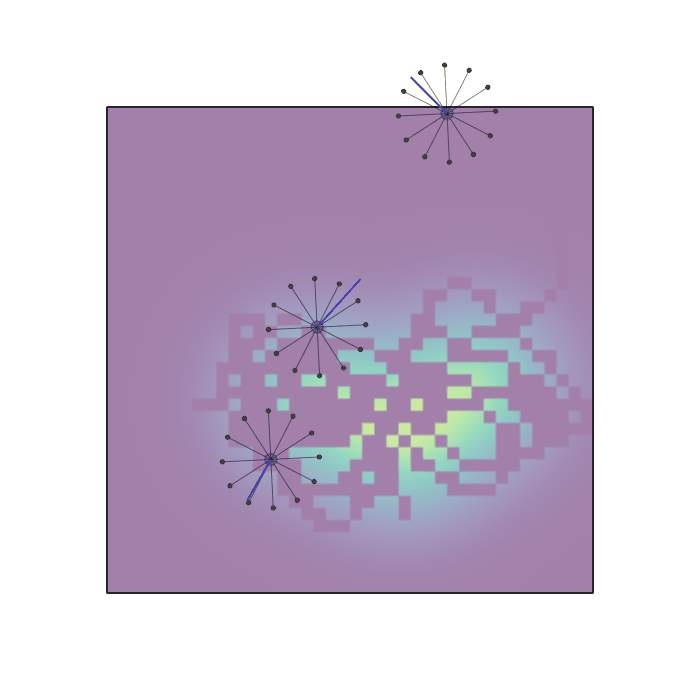
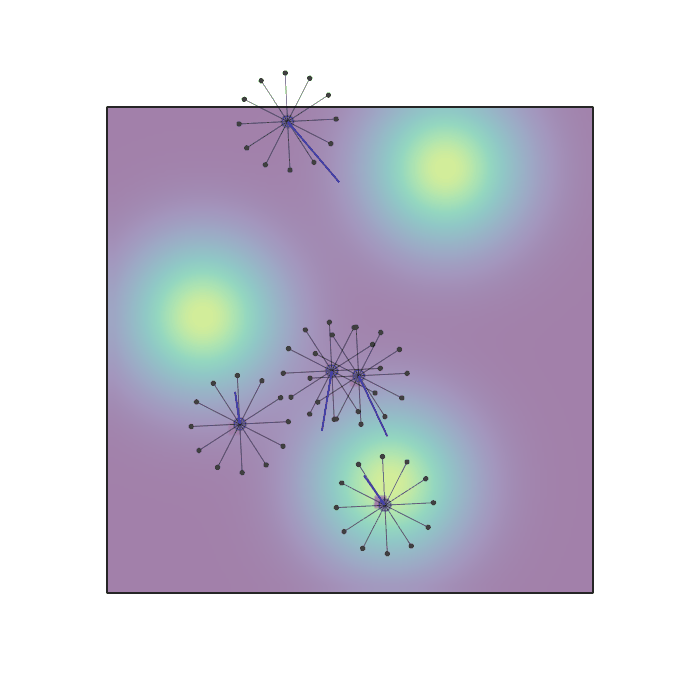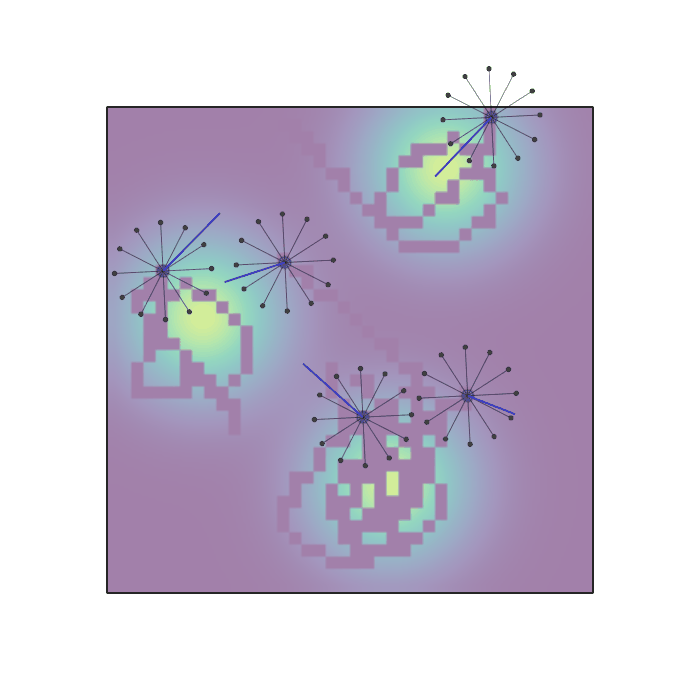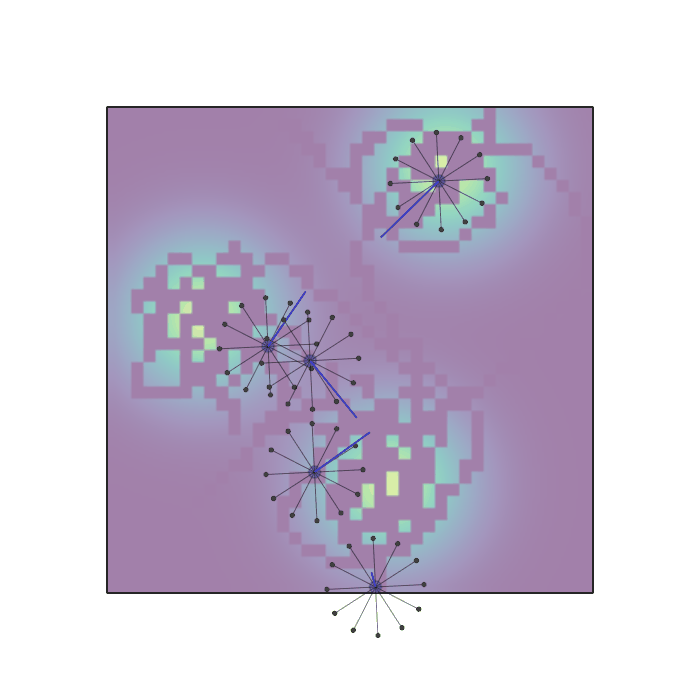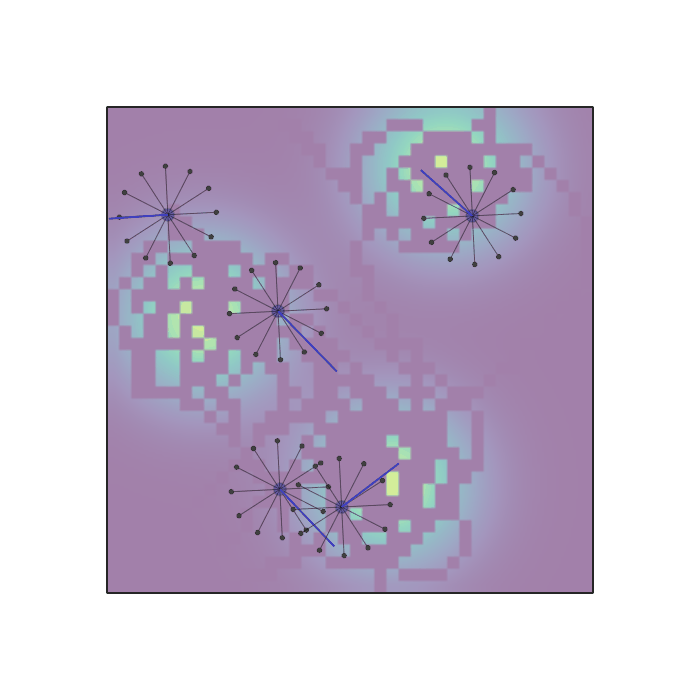
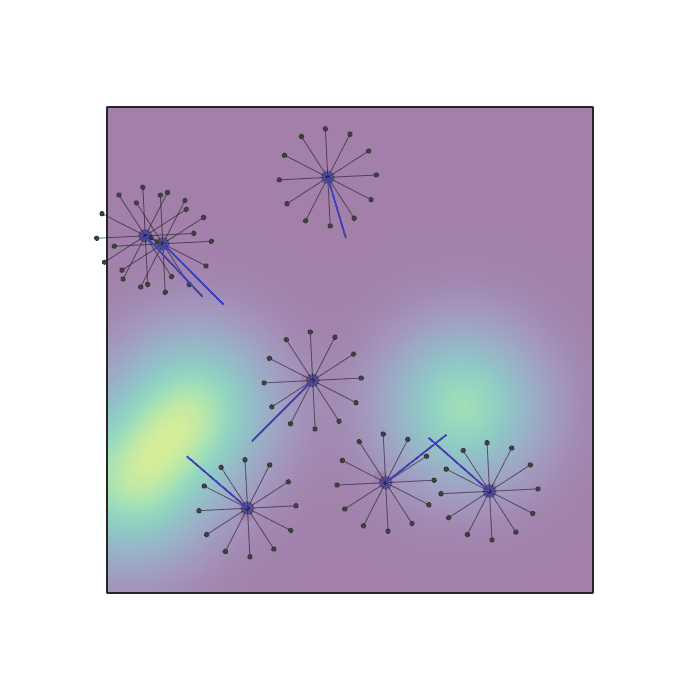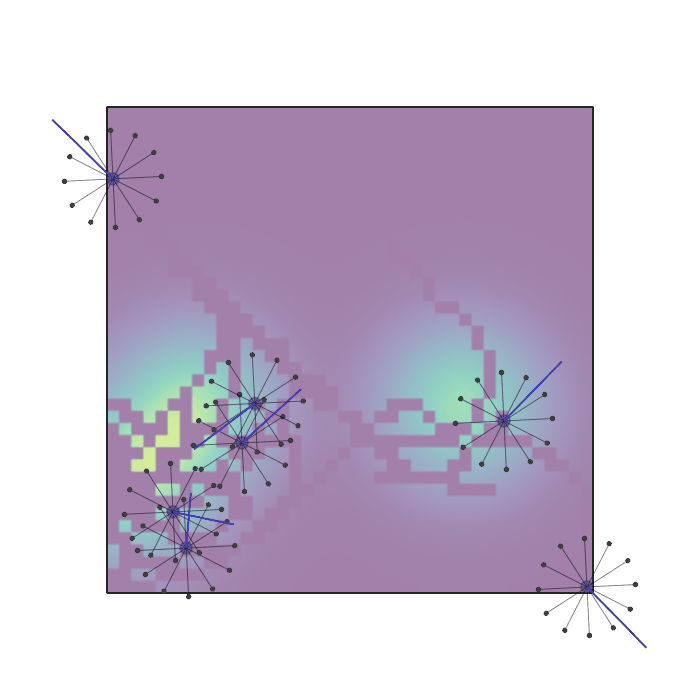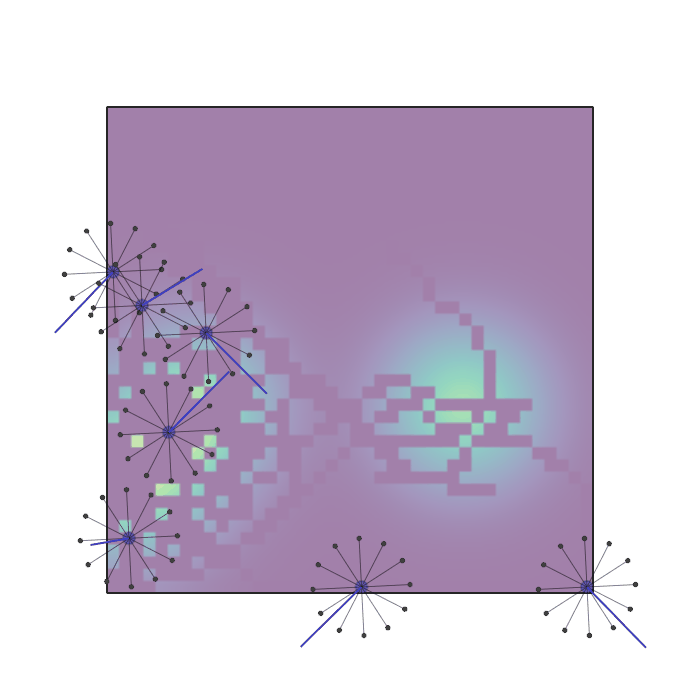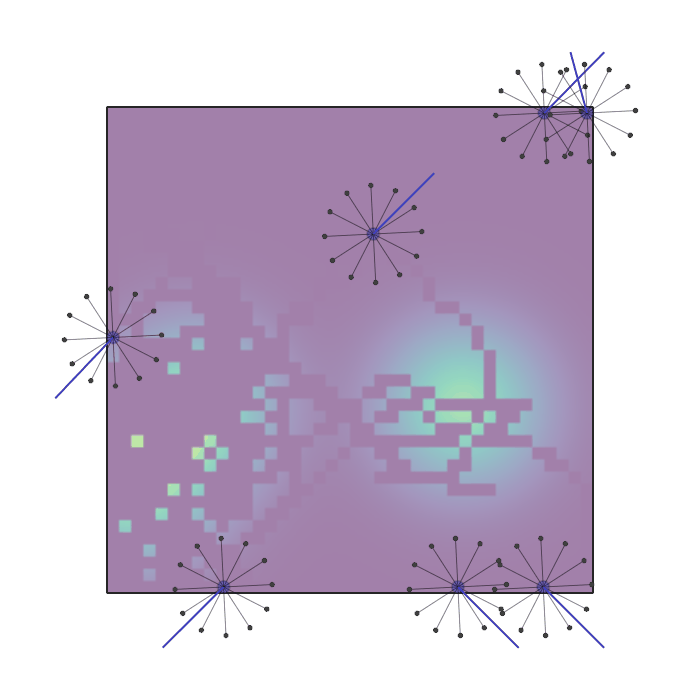
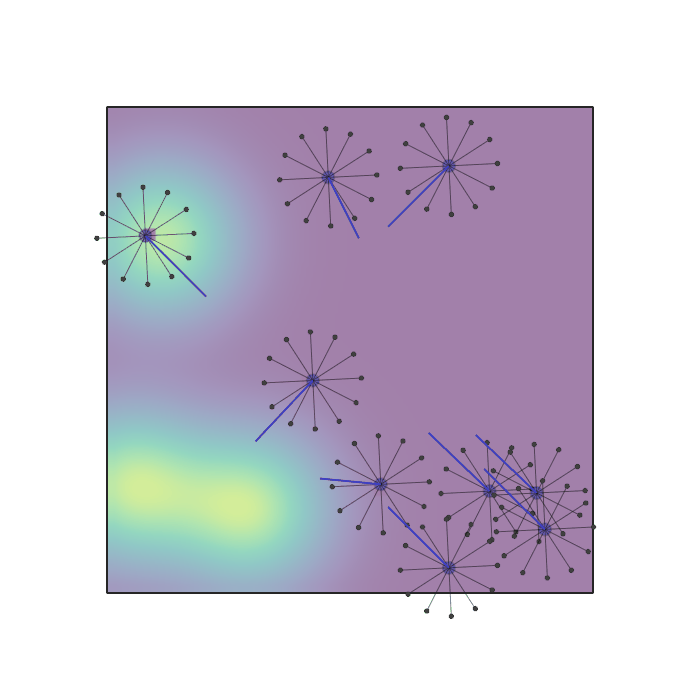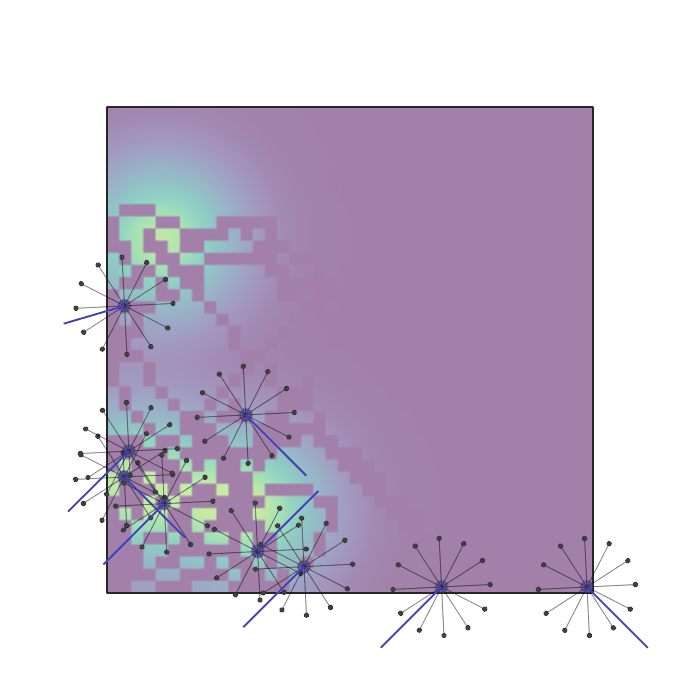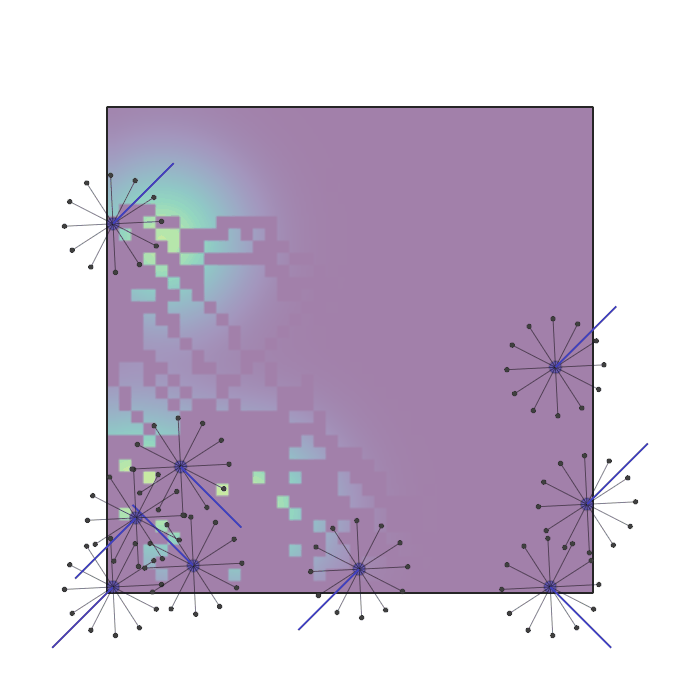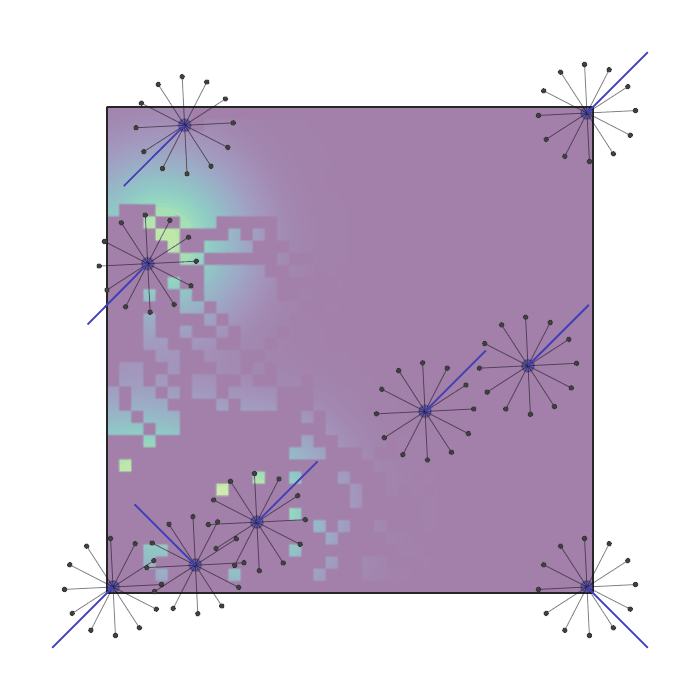
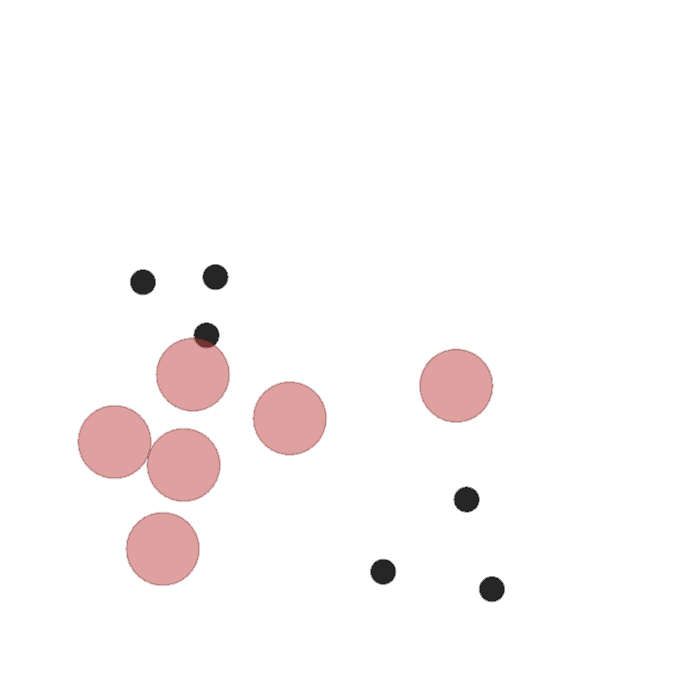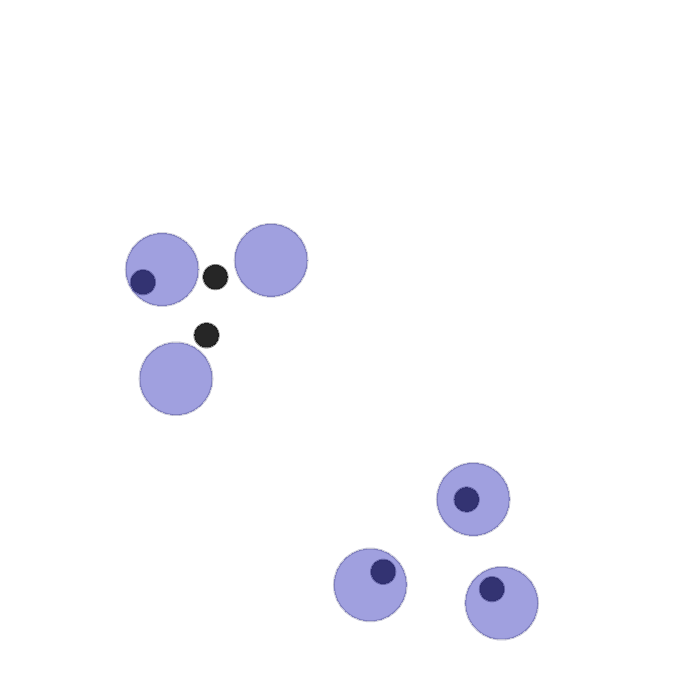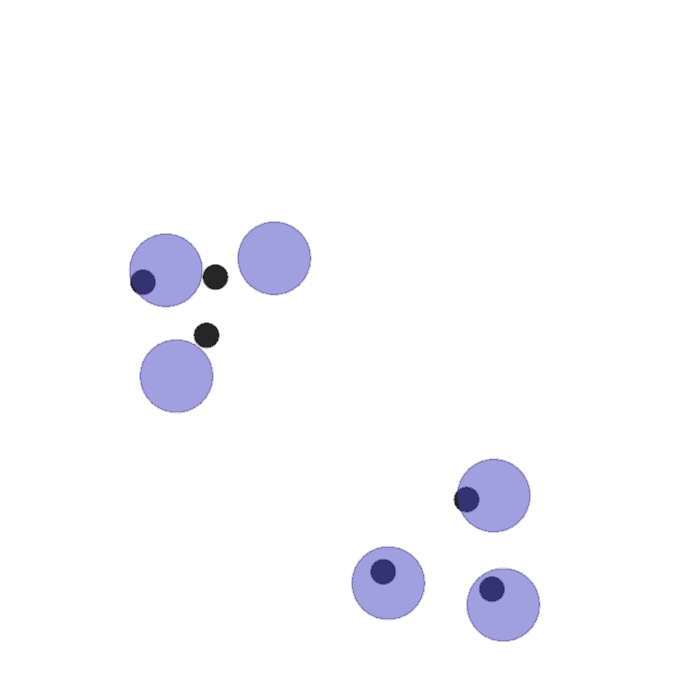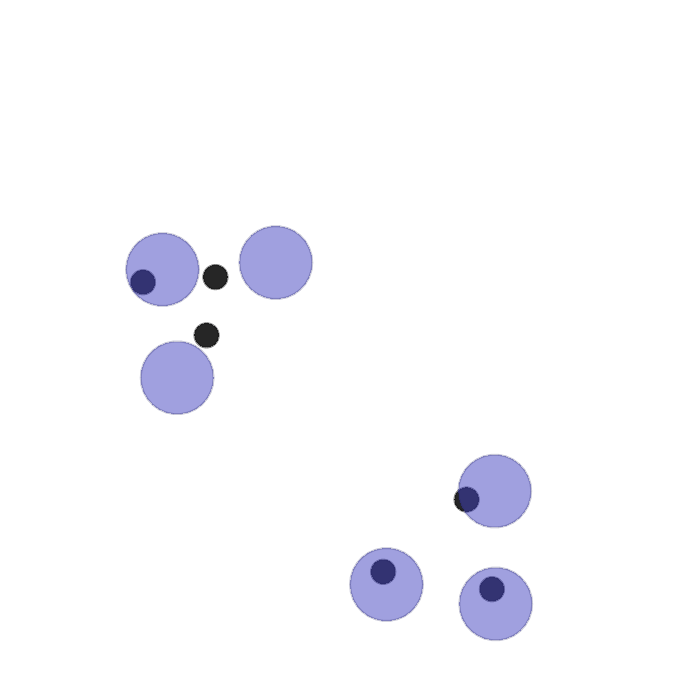
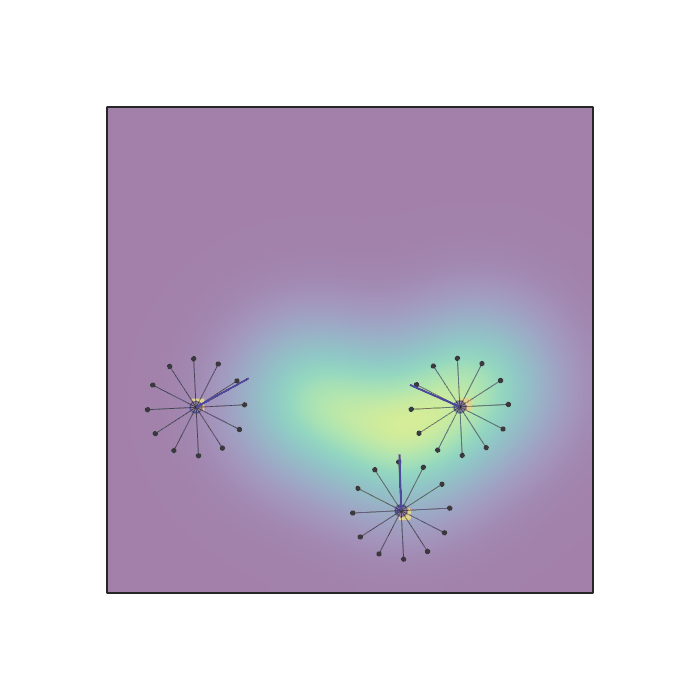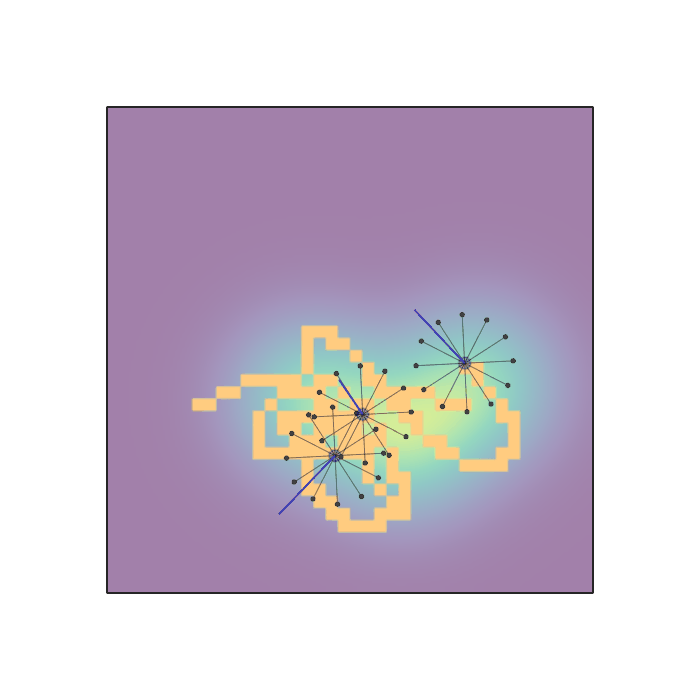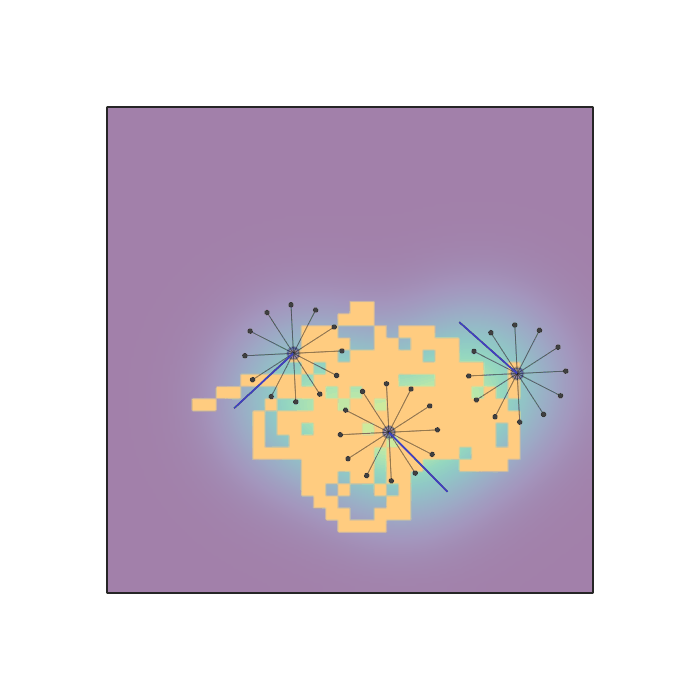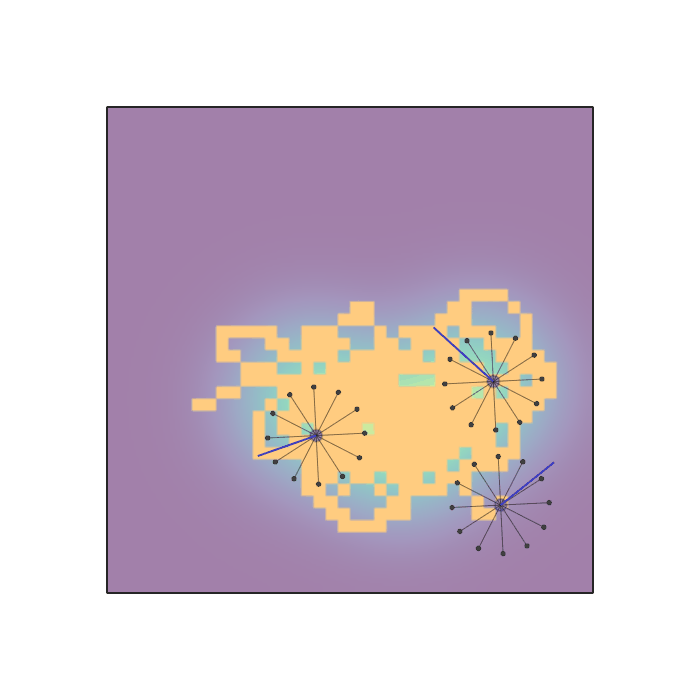
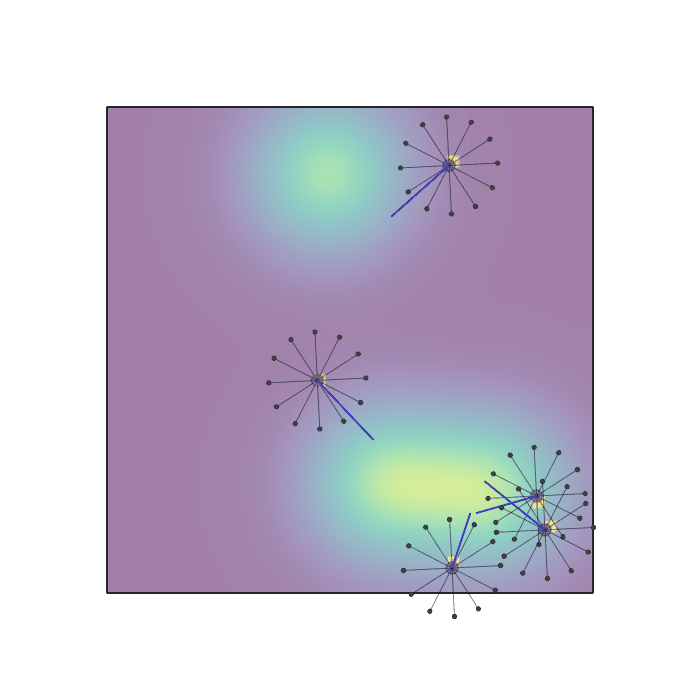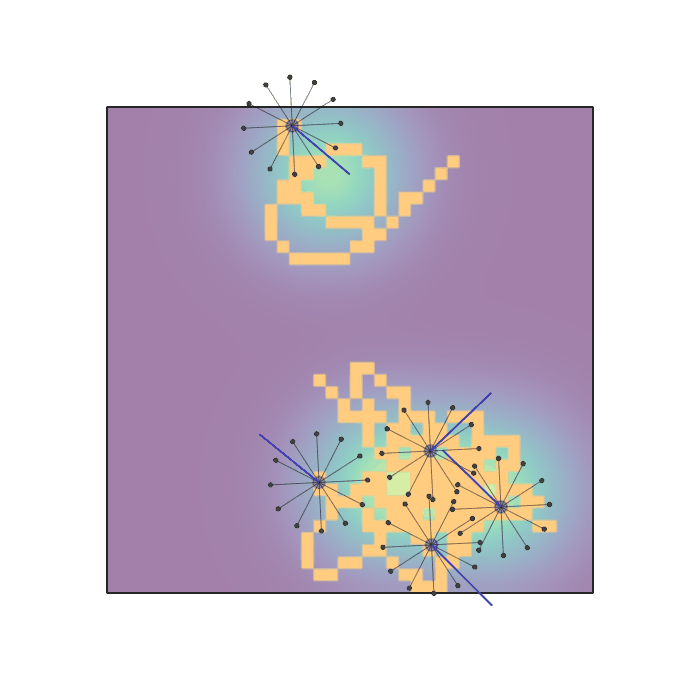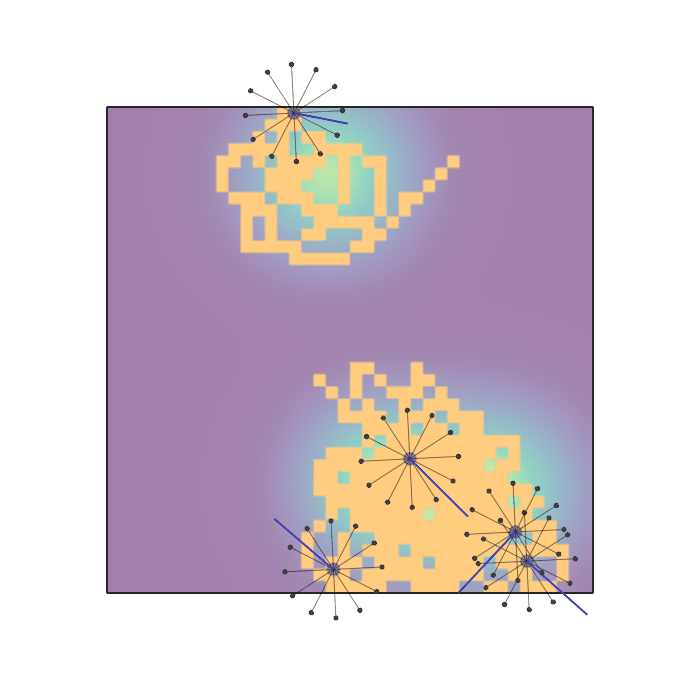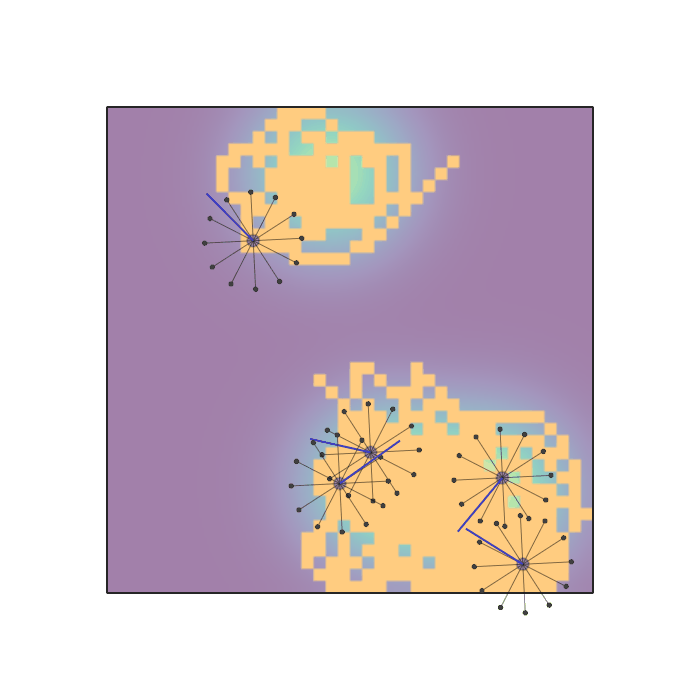
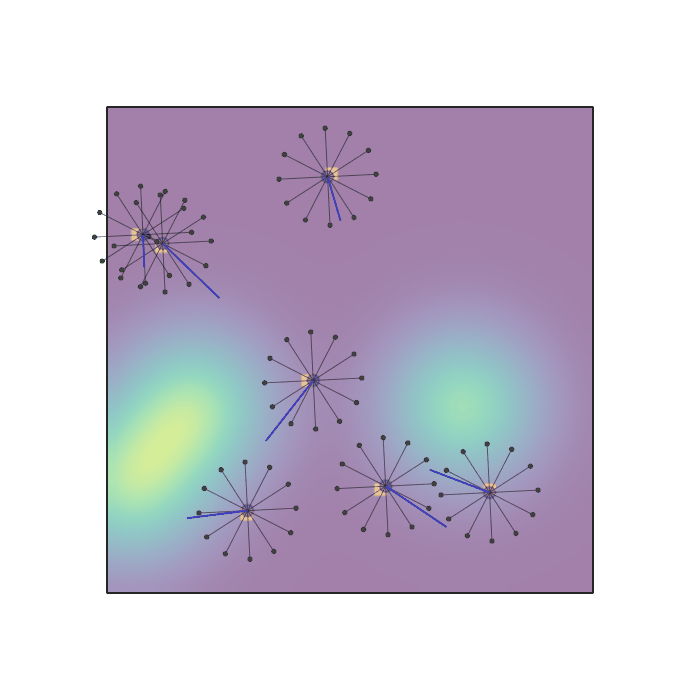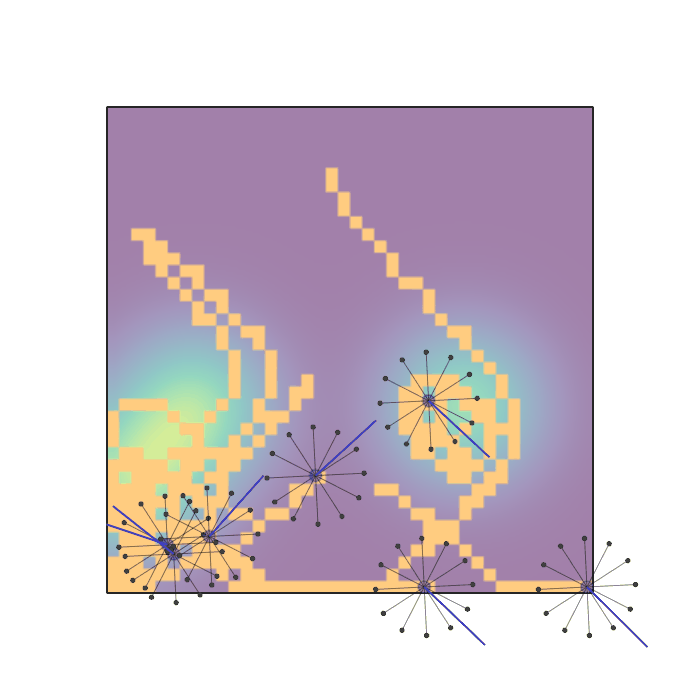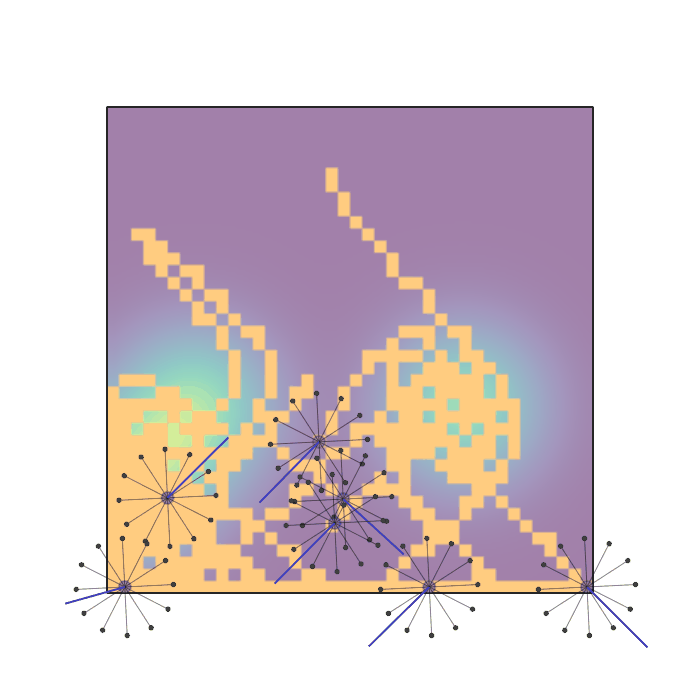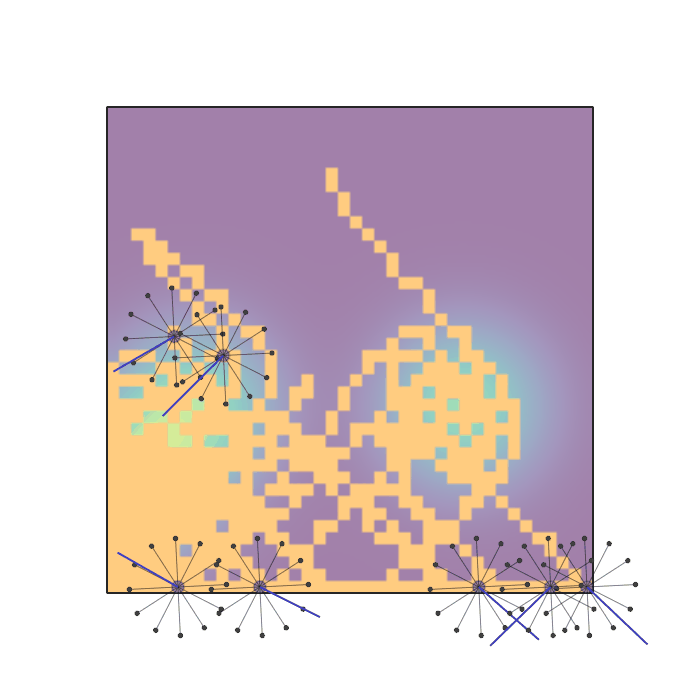
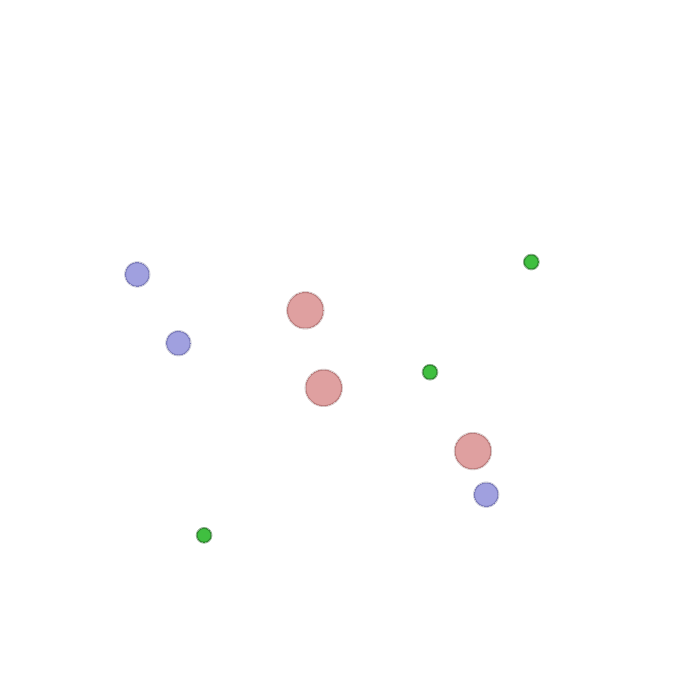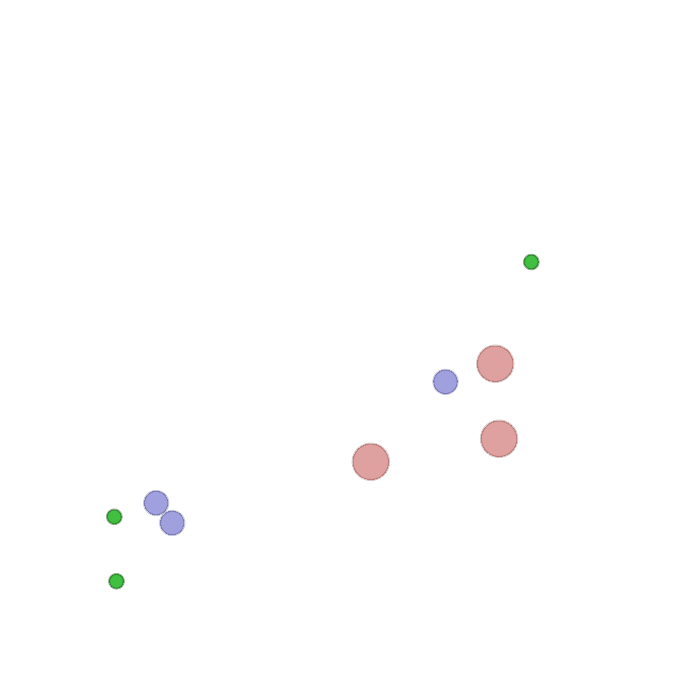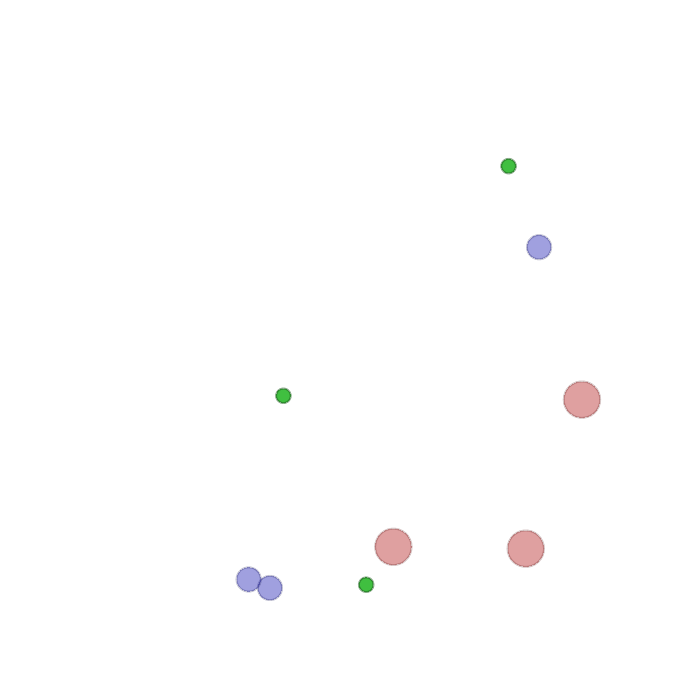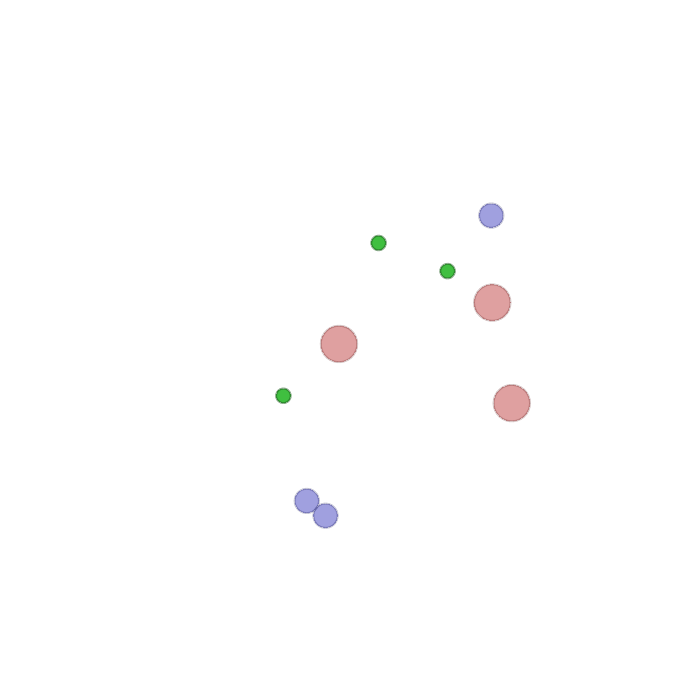
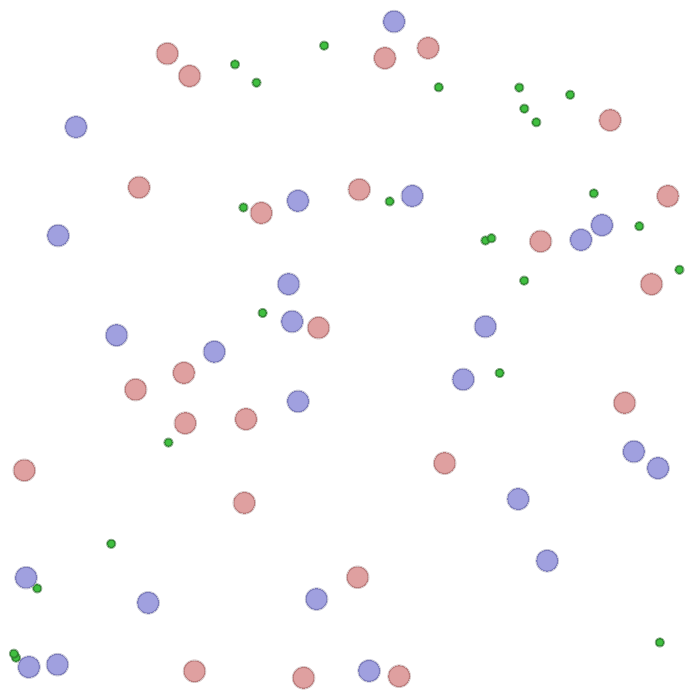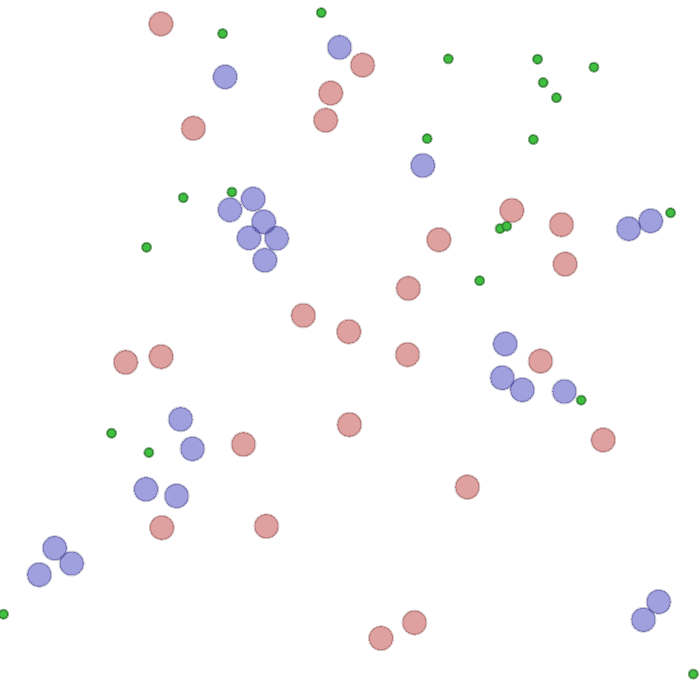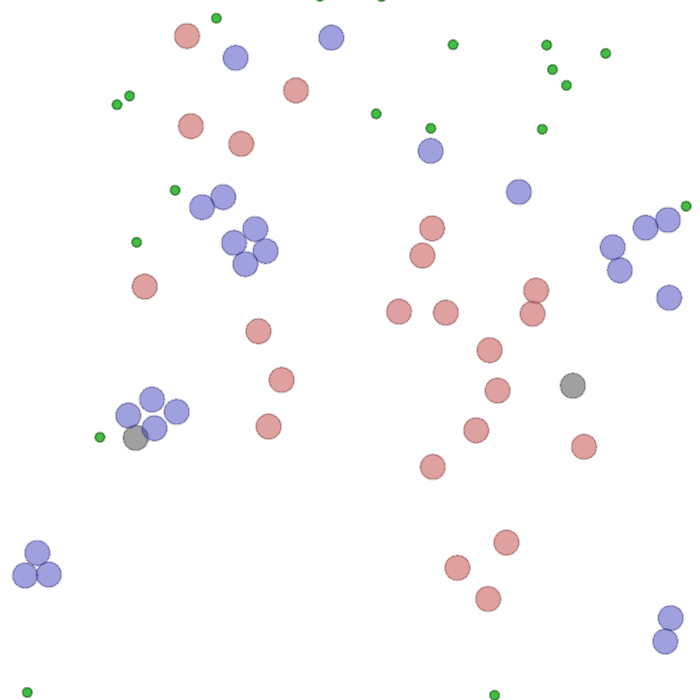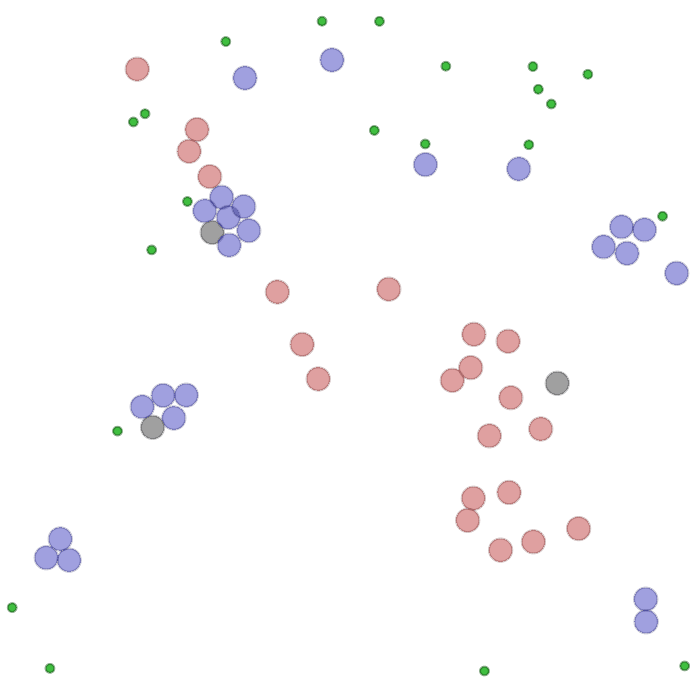
Examples of multi-robot scenarios for different initial conditions and number of robots. It is interesting to see that some aspects of the environment do not scale with the team size, e.g., the size and weight of the box in the reverse transport scenario, the number of hot spots in the sampling scenario or the size of the arena in the navigation scenario. From top to bottom: reverse transport, navigation, sampling, food collection, grassland, adversarial.
|




|

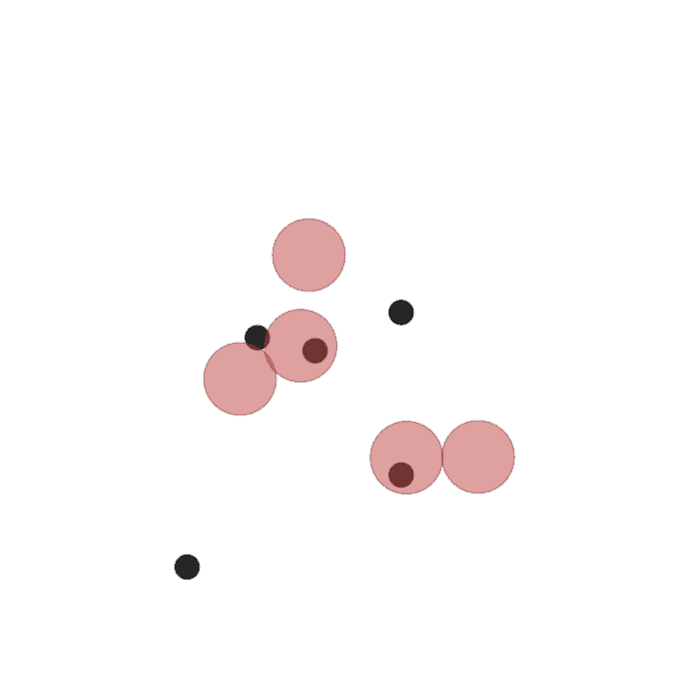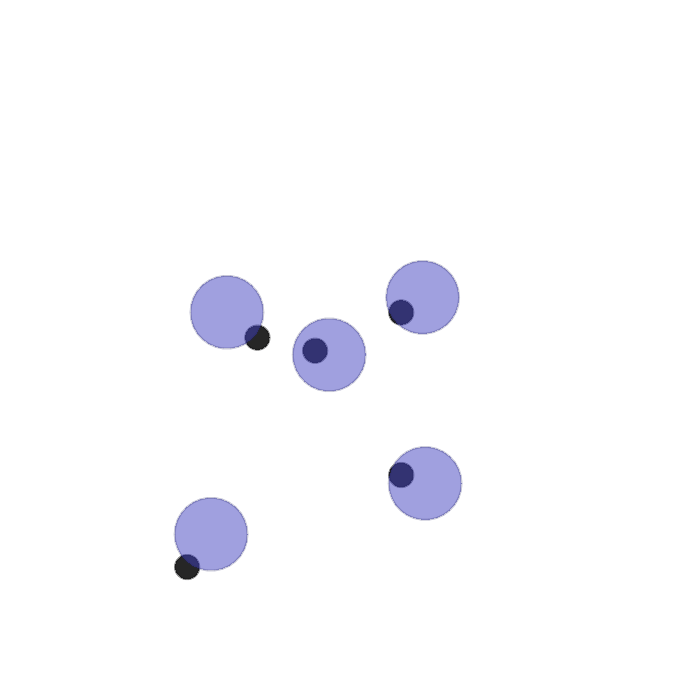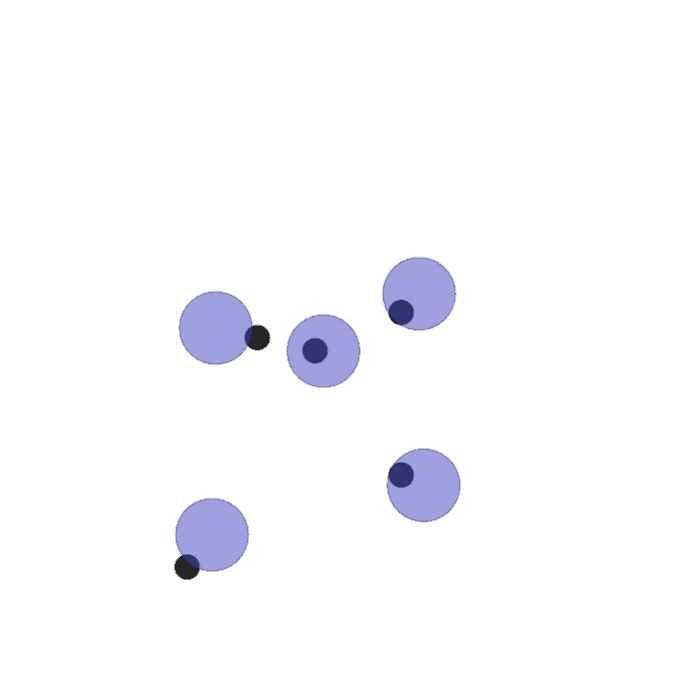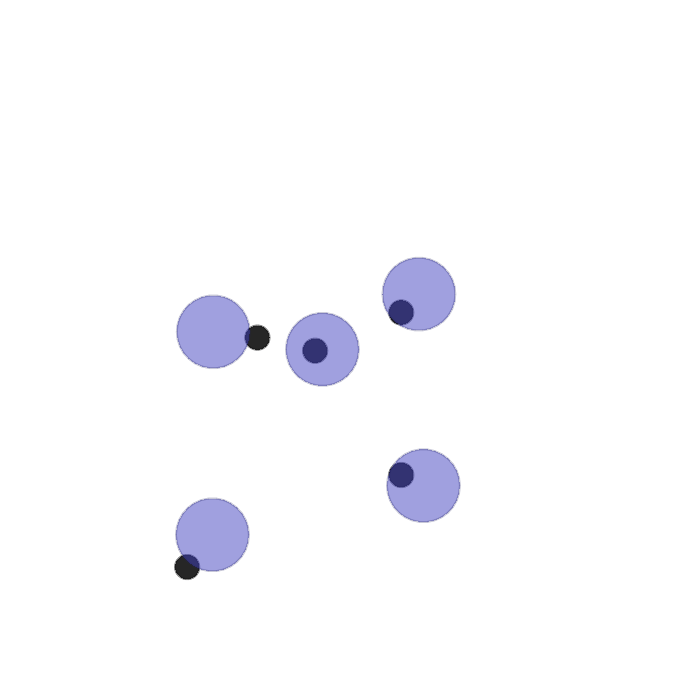
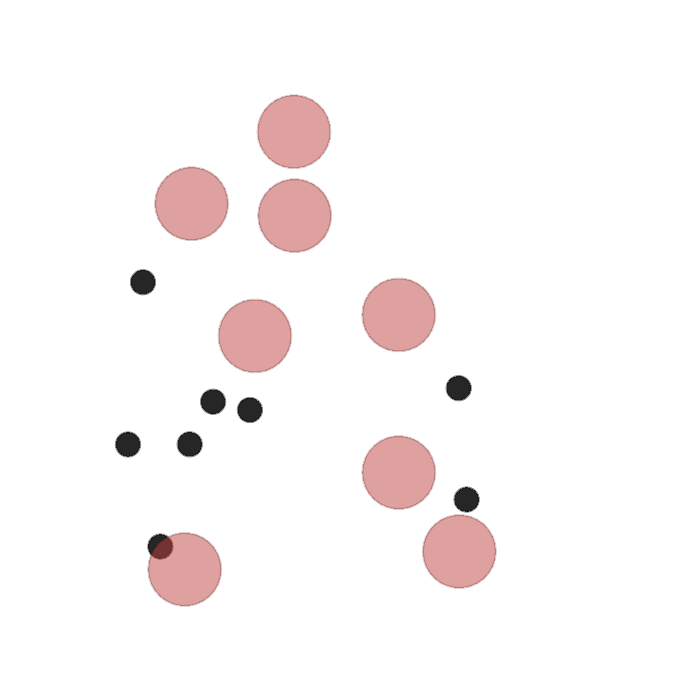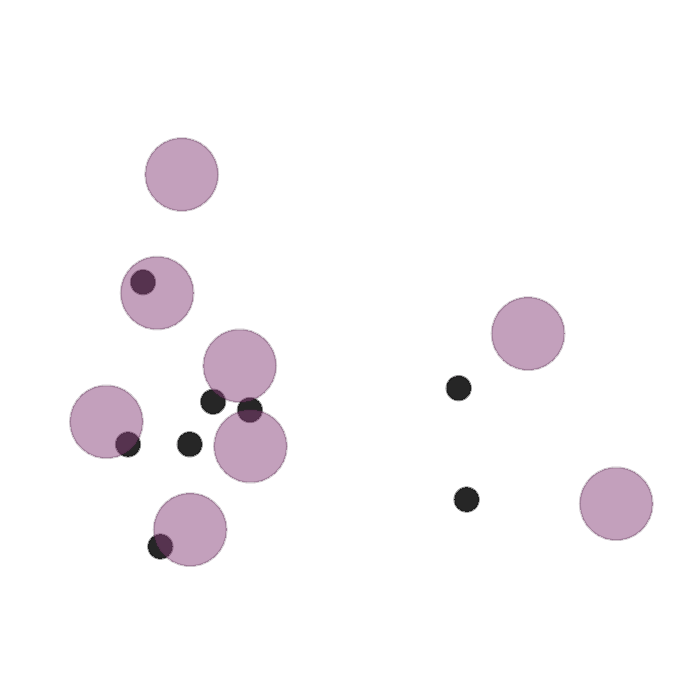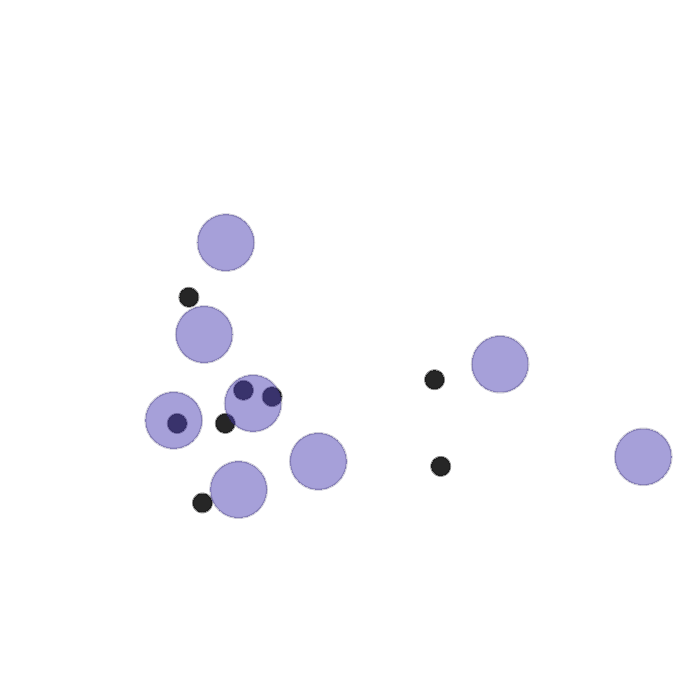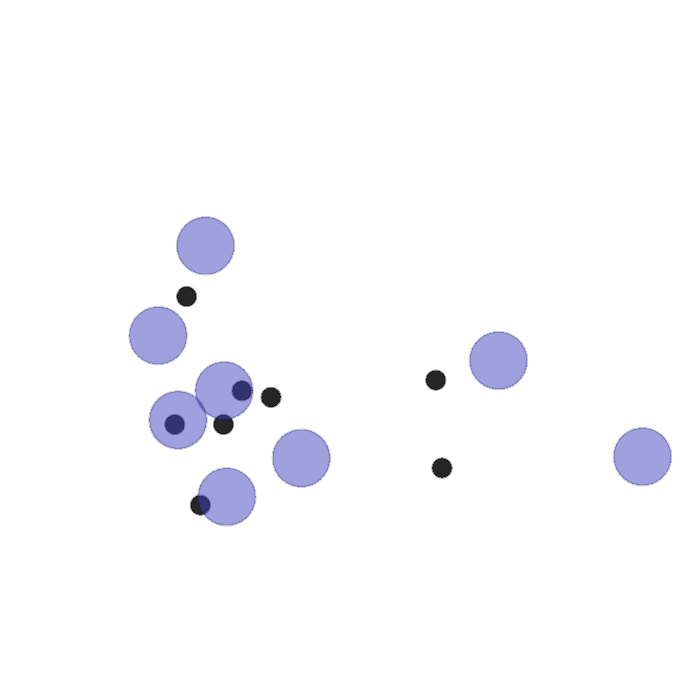
|
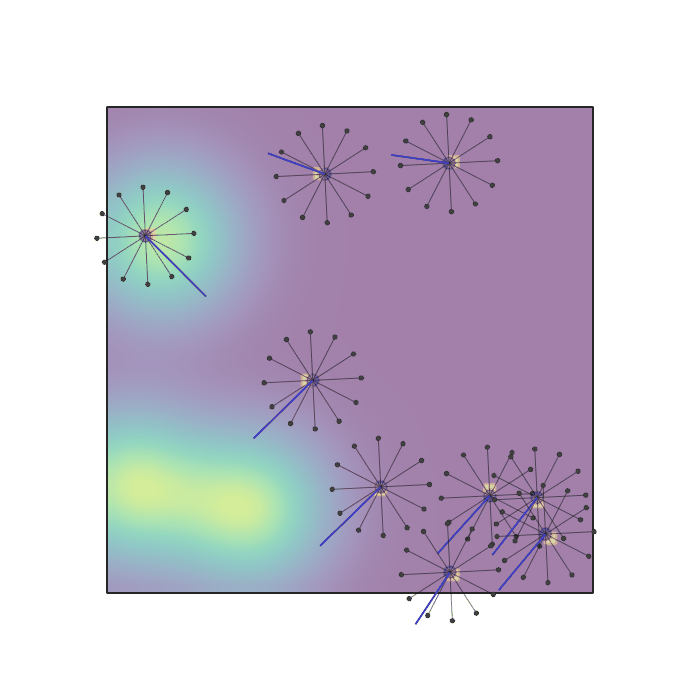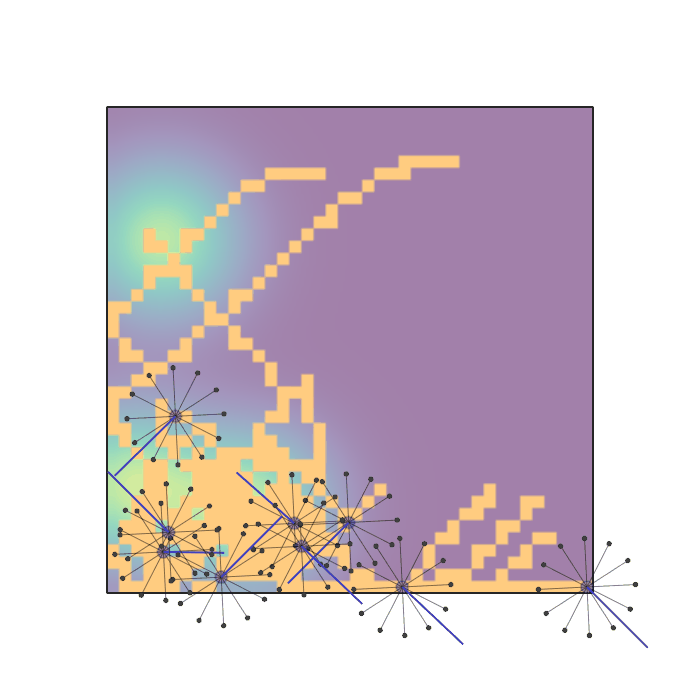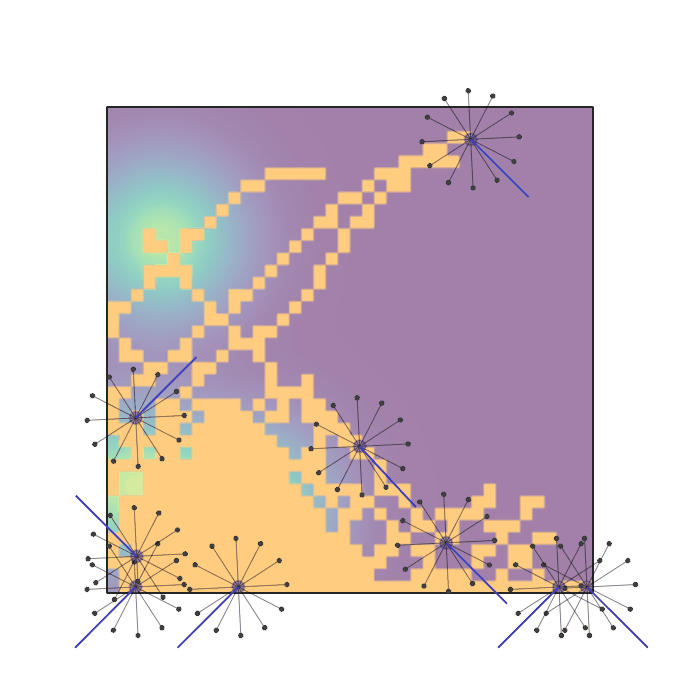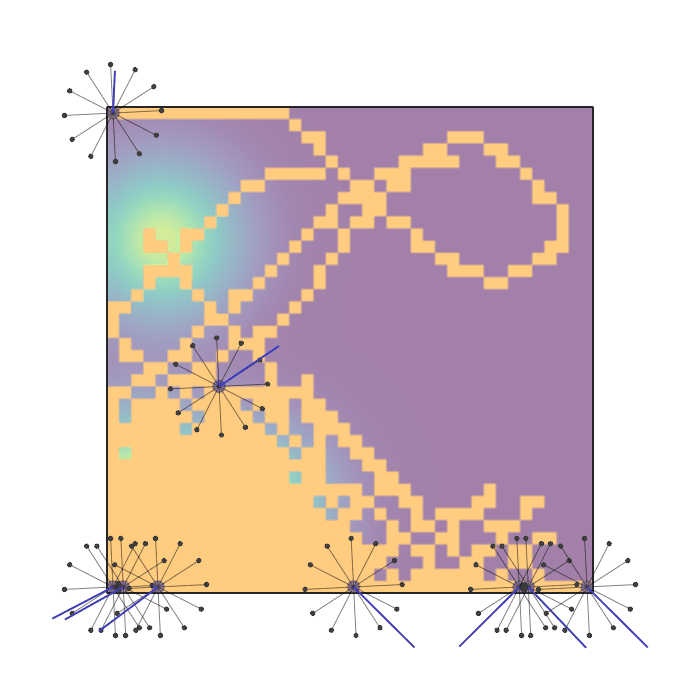
|



|
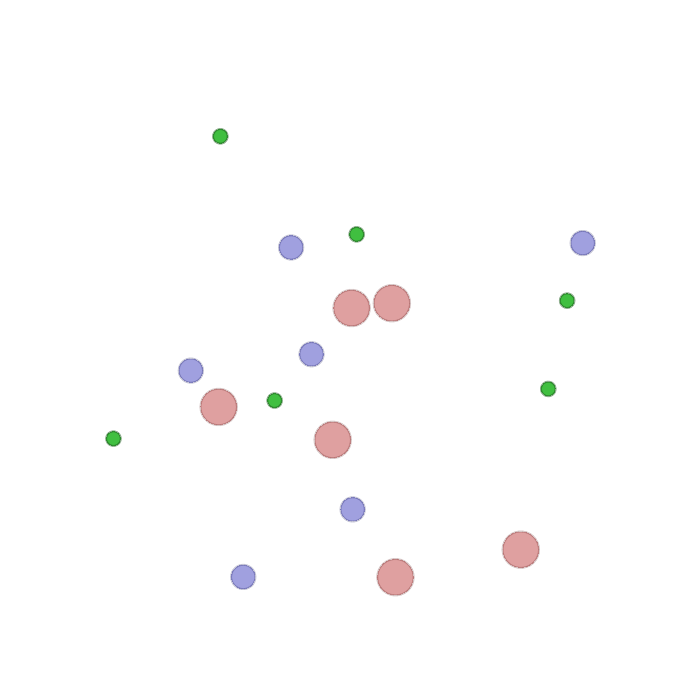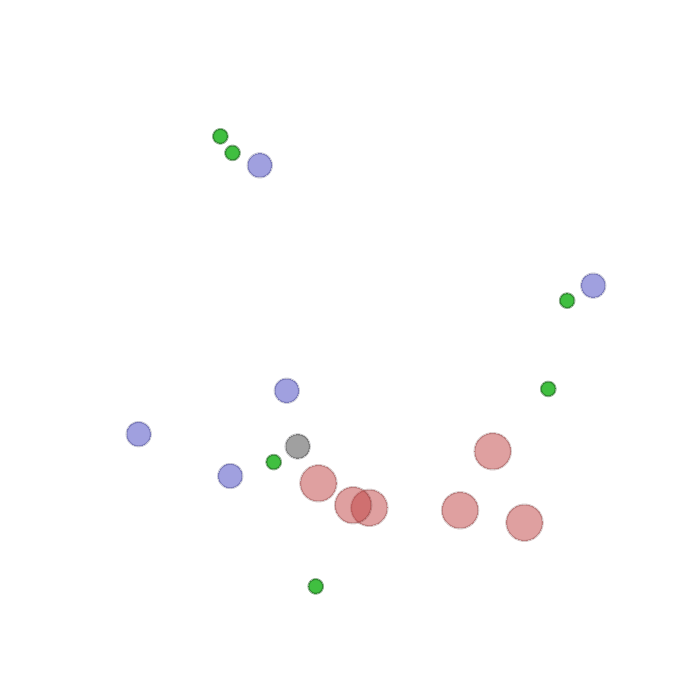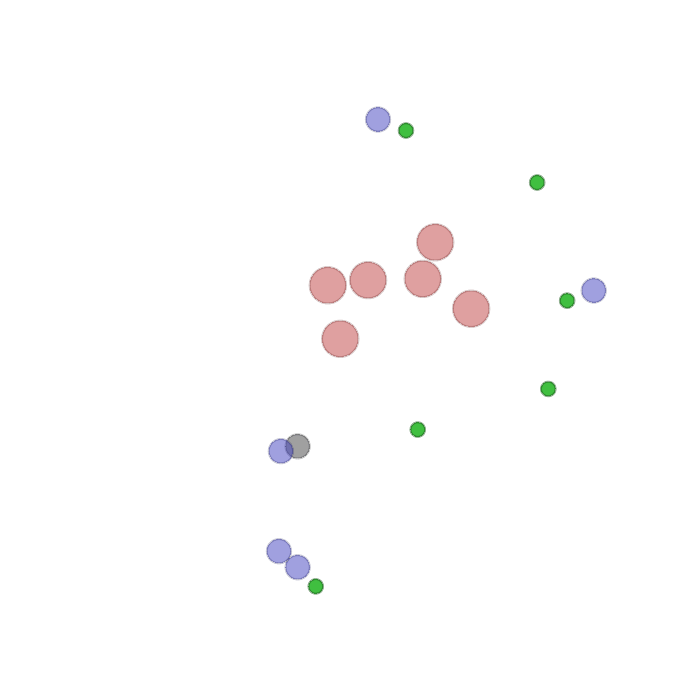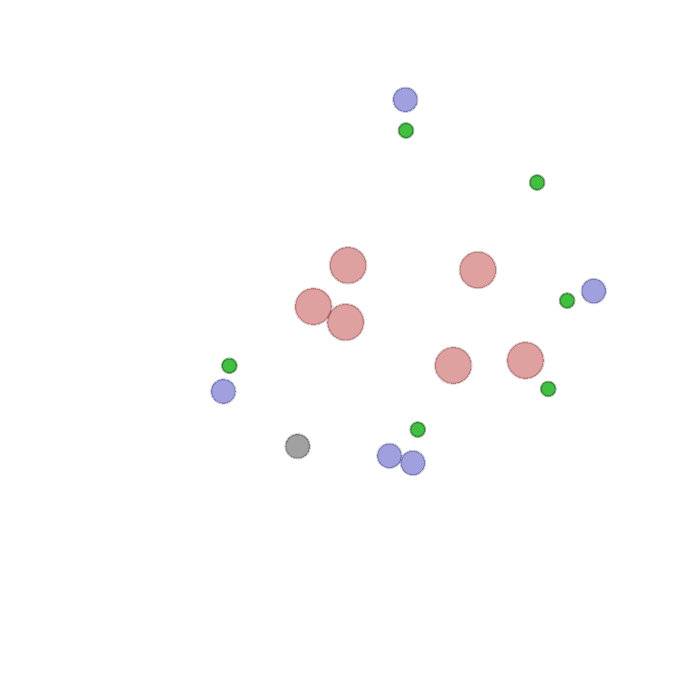

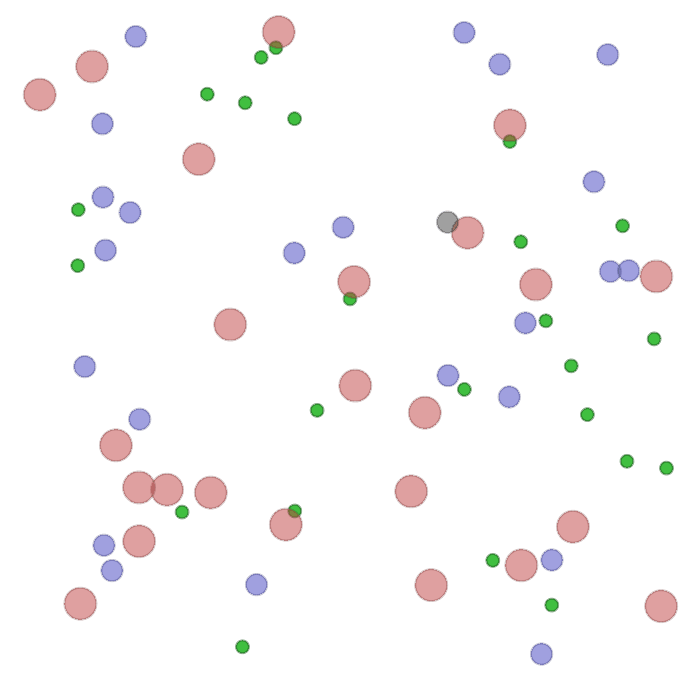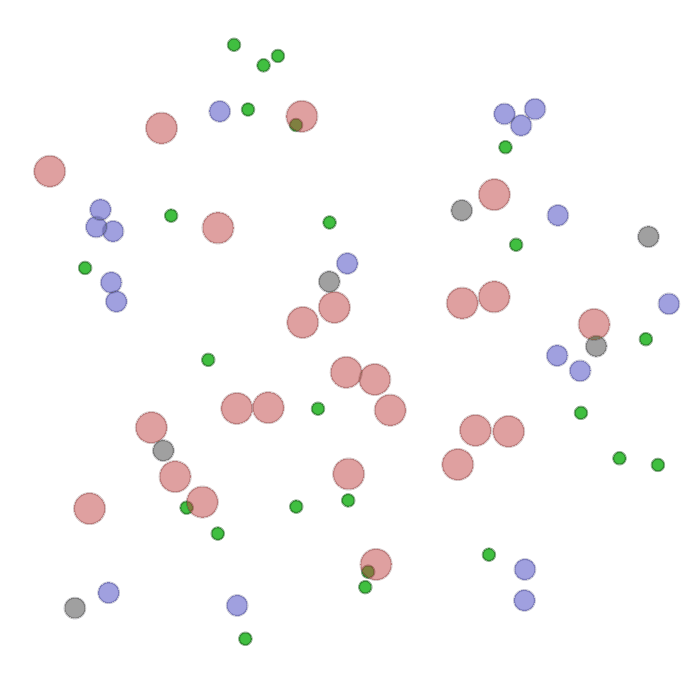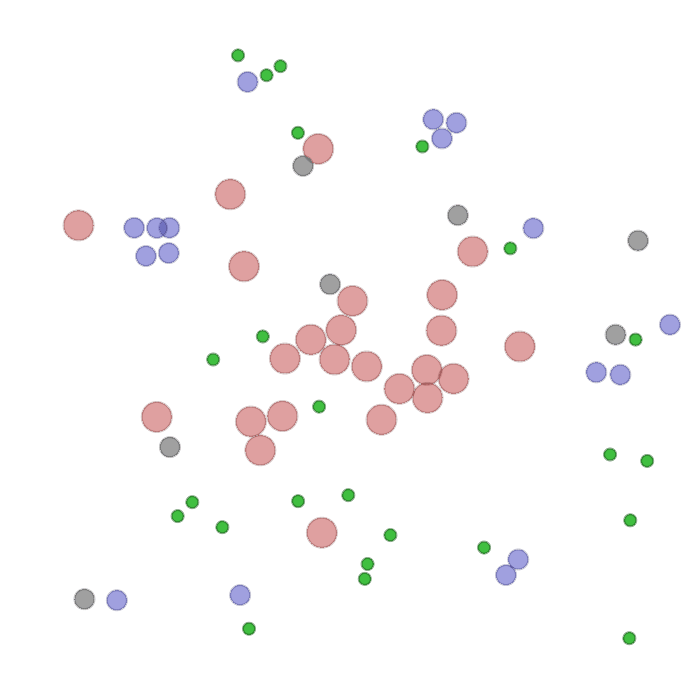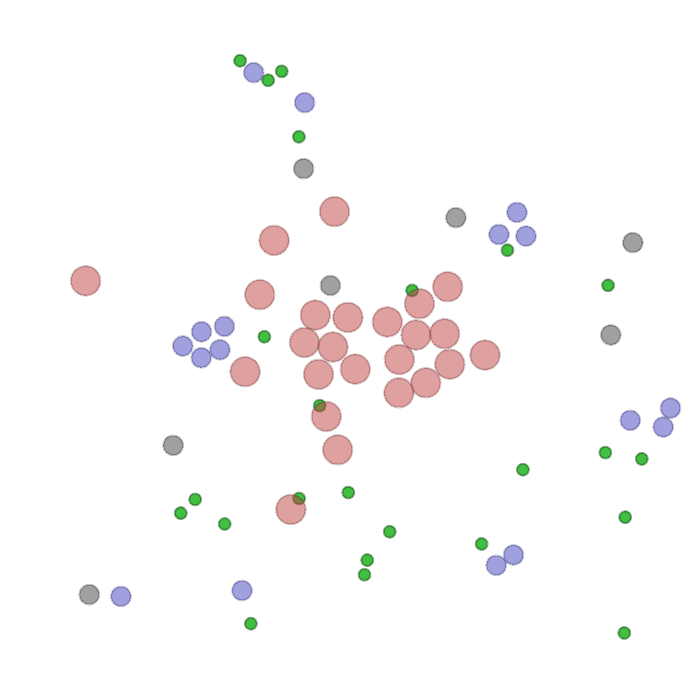
|



|
|
We further validate our method in a realistic robot setting using MuJoCo, a fast yet realistic physics simulator. Specifically, we use the Multi-agent MuJoCo benchmark, where the task is to learn a coordination policy for a Half Cheetah robot. The robot has 6 joints, where each joint is a different agent and distribution is achieved by enabling agent communication only with the adjacent joints, enforced by a ring graph topology.
|

|
|
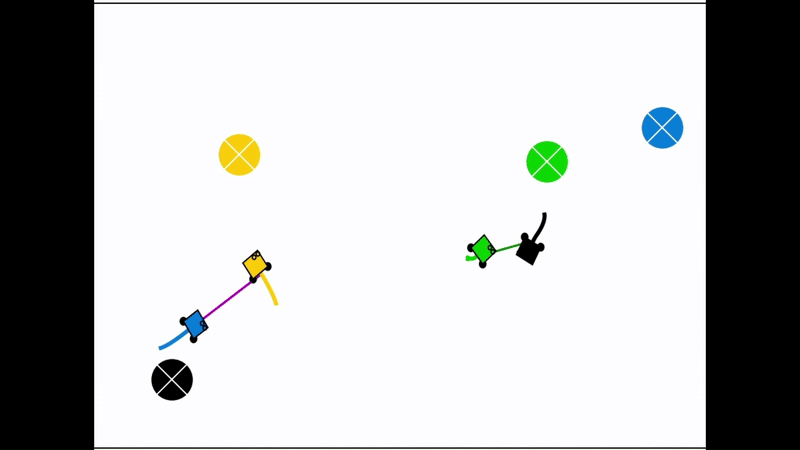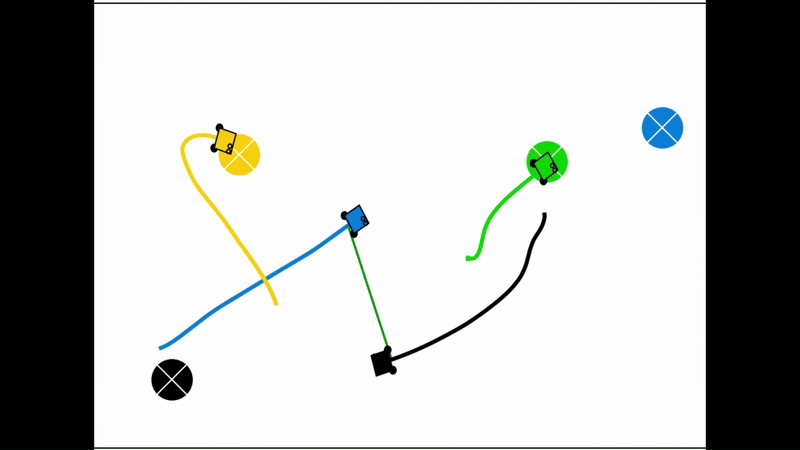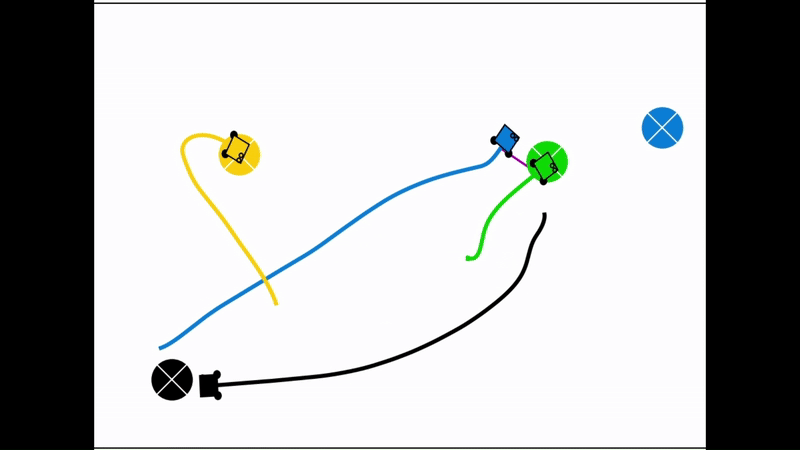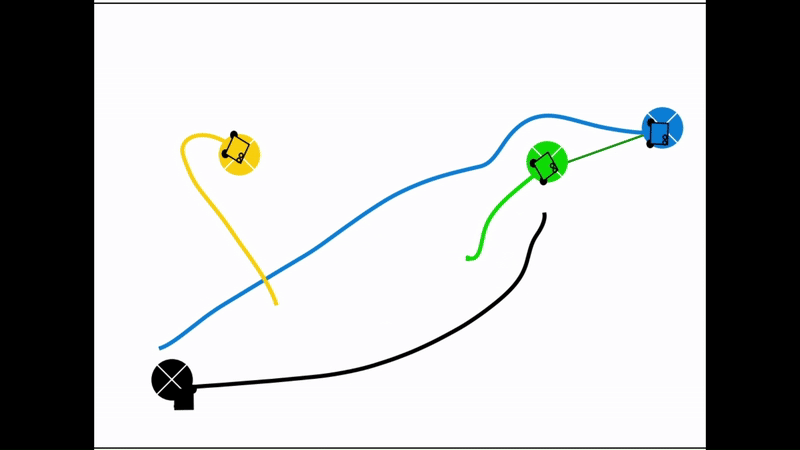
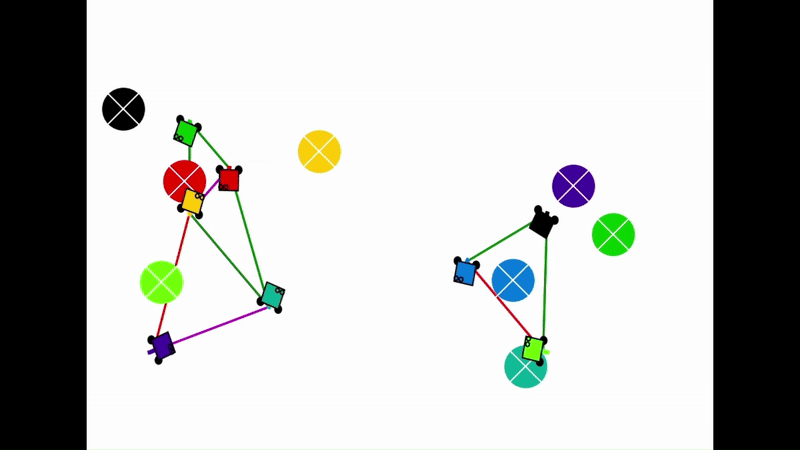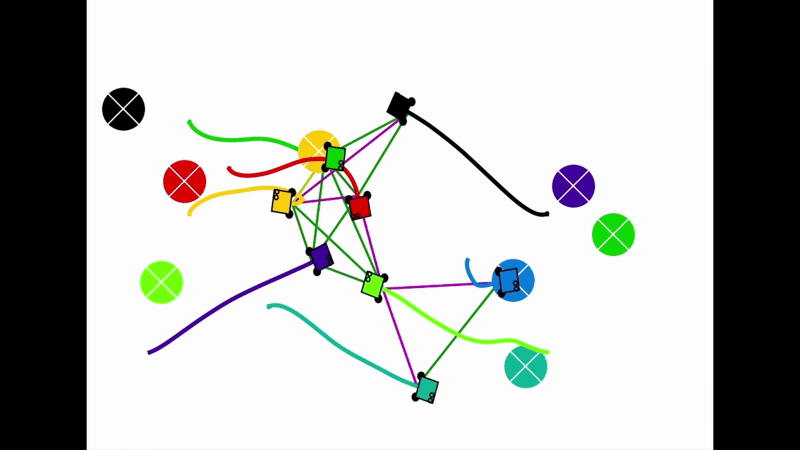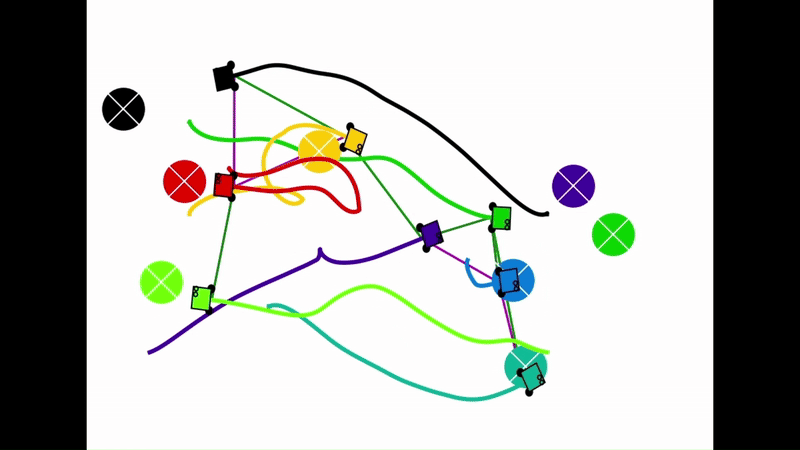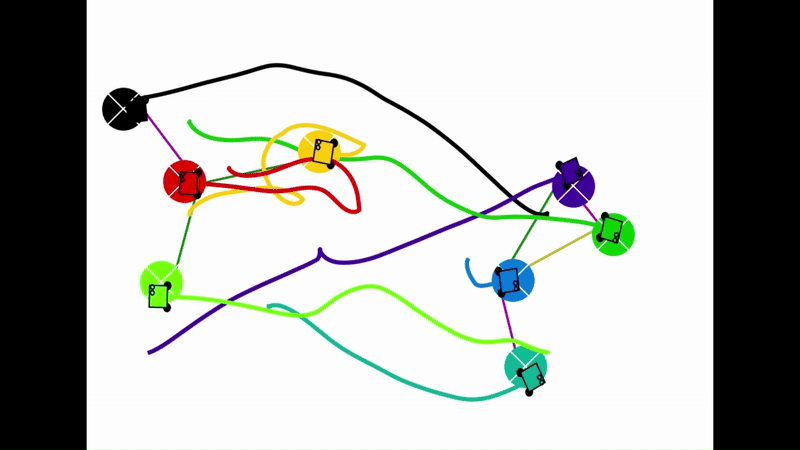
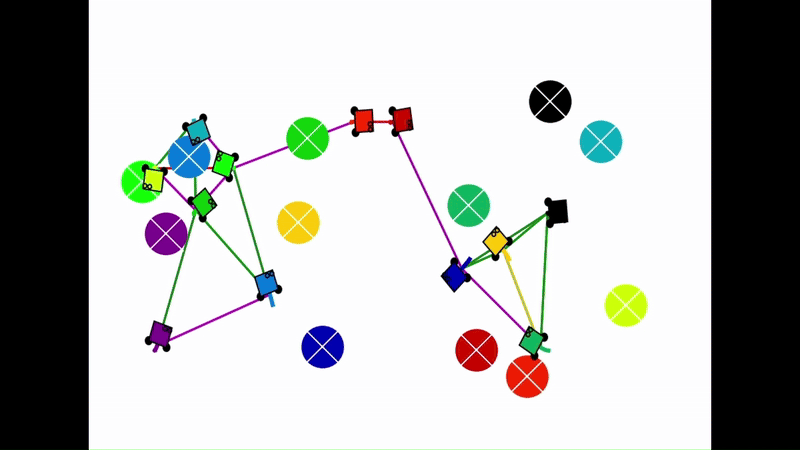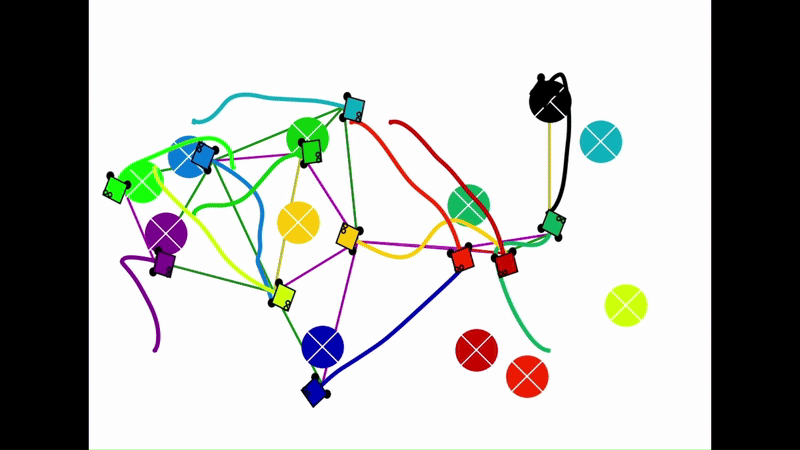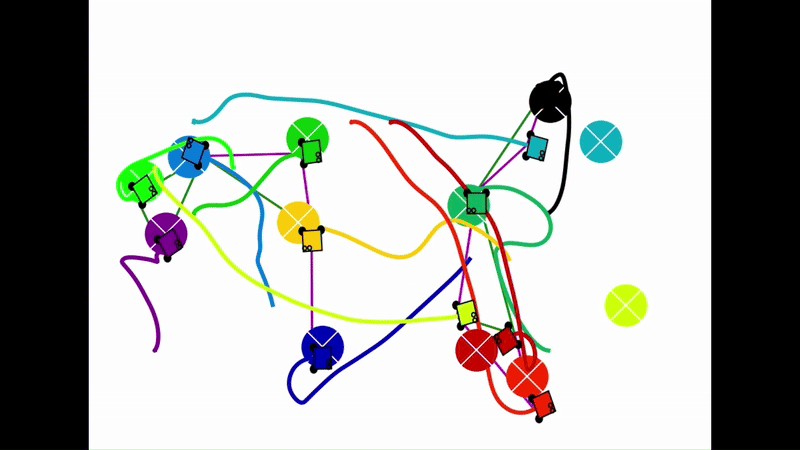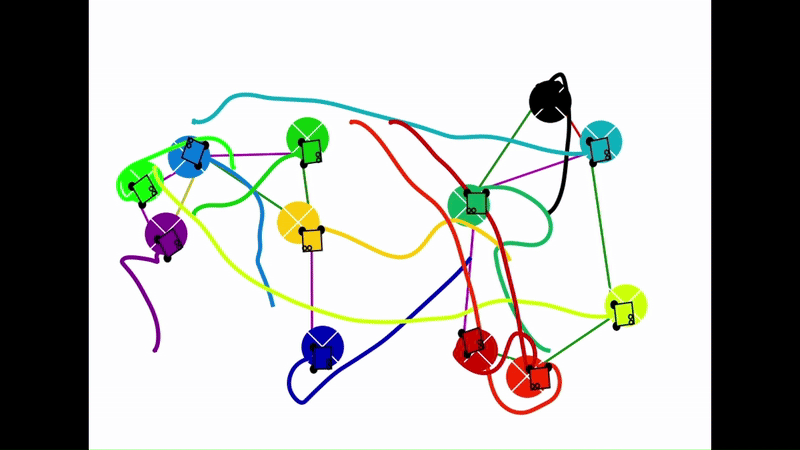
Qualitative results of the pH-MARL policy for multi-robot navigation in the Robotarium simulator. On the 4 robot case, communications are perfect, whereas the others operate under imperfect communications. In the imperfect communication cases, magenta links denote delays, red links denote packet loss, yellow links denote disturbances, and green links denote unperturbed links.
|
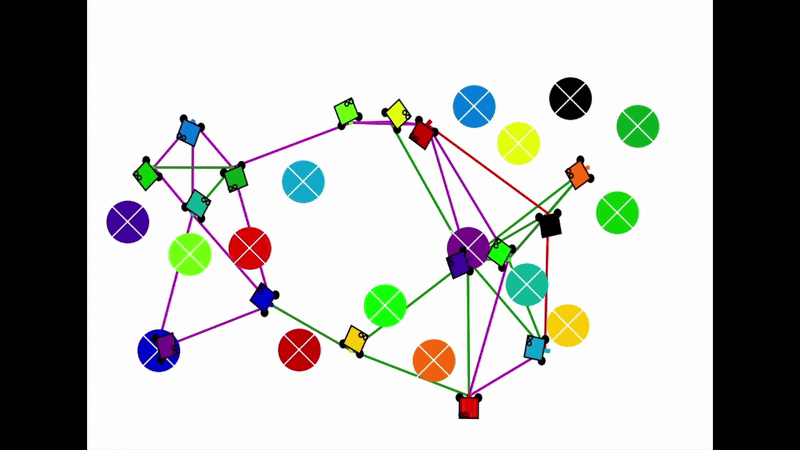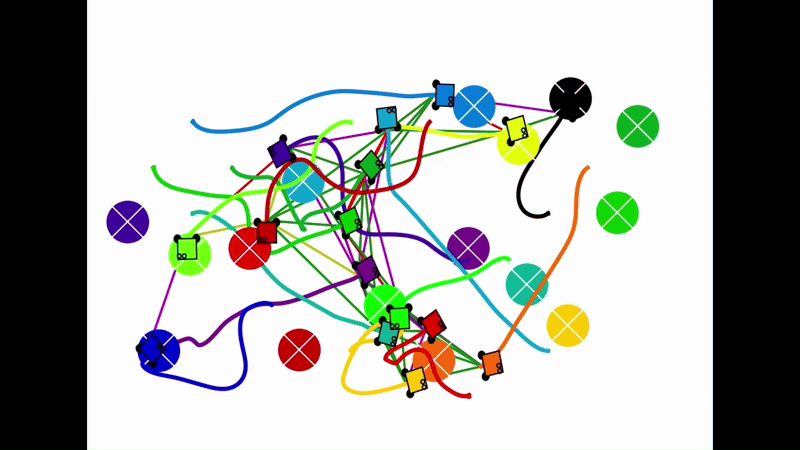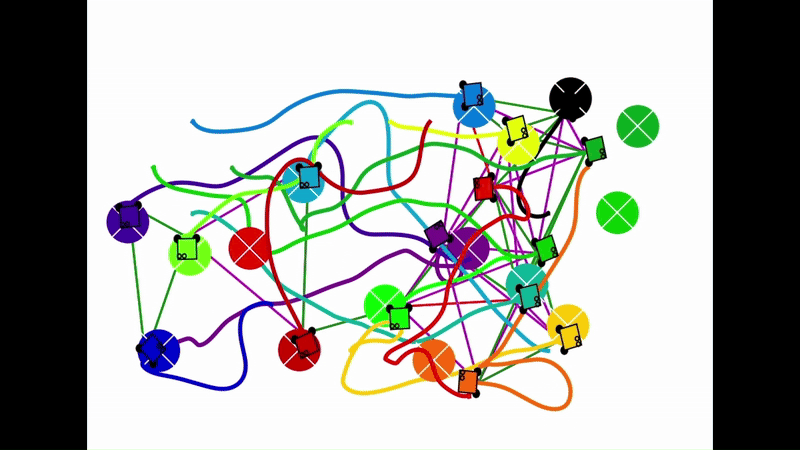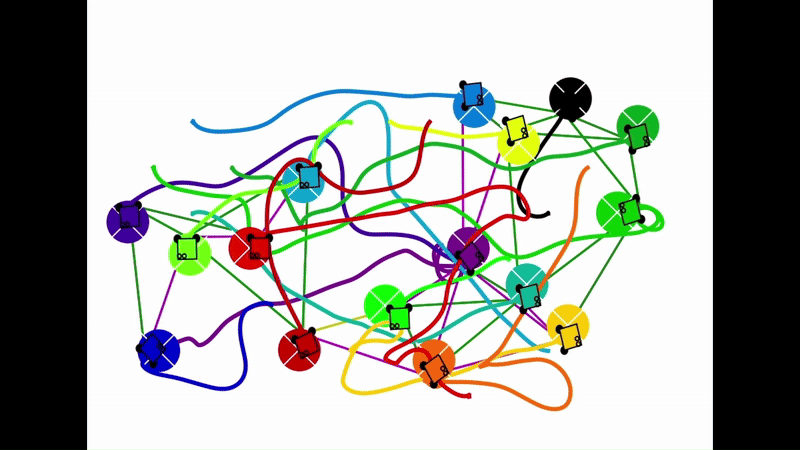
|




|
Code
Citation
If you find our papers/code useful for your research, please cite our work as follows.
E. Sebastian, T. Duong, N. Atanasov, E. Montijano, C. Sagues. Physics-Informed Multi-Agent Reinforcement Learning for Distributed Multi-Robot Problems. IEEE Transactions on Robotics, 2025.
@article{sebastian24phMARL,
author = {Eduardo Sebasti\'{a}n AND Thai Duong AND Nikolay Atanasov AND Eduardo Montijano AND Carlos Sag\"{u}\'{e}s},
title = {{Physics-Informed Multi-Agent Reinforcement Learning for Distributed Multi-Robot Problems}},
journal = {IEEE Transactions on Robotics},
year = {2025}
}
Acknowledgements
This work has been supported by ONR N00014-23-1-2353 and NSF CCF-2402689 (ExpandAI), by Spanish projects PID2021-125514NB-I00, PID2021-124137OB-I00 and TED2021-130224B-I00 funded by MCIN/AEI/10.13039/501100011033, by ERDF A way of making Europe and by the European Union NextGenerationEU/PRTR, DGA T45-23R, a Spanish grant FPU19-05700 and a US-Spain Fulbright grant.
|